
Optimising Archive Node Storage for Tezos
For the past few years, Tarides has been responsible for the storage component of Tezos, from L1 and L2 shells up to the Tezos protocol. In 2022, our main focus was on improving storage performance and UX for running nodes and bakers. Our efforts resulted in significant improvements, including reducing the storage requirements for rolling nodes by 10x and decreasing the memory usage of the storage layer by 80%. We also maintain core storage APIs necessary to scale the TPS of the network. But we didn't stop there! This year, we've already worked on improving the performance of archive nodes and delivered the project last month. In this blog post, we'll take a closer look at our work and what it means for the future of Tezos.
Last year we released a garbage collector (GC) for the irmin-pack backend to reclaim disk space. The irmin-pack backend is notably used by Octez to support the Tezos blockchain storage on disk. In this context, the Irmin GC is used to perform context pruning by rolling nodes. This operation reclaims disk space by deleting old blocks that are no longer required to participate in the Tezos consensus algorithm. In Git terms, the rolling nodes only maintain a shallow history of the blockchain. On the other end, archive nodes retain the entirety of the blockchain to ensure integrity. The Irmin GC has the additional benefit of compacting the data on disk, hence improving the performances of disk operations due to better data locality.
Following the context pruning release in Octez v16, we focused on improving the performances of the Irmin GC, both in its disk usage and memory. We also brought the optimisation benefit of data compaction to archive nodes. As the Tezos blockchain keeps growing, the archive nodes storage requirements are also becoming problematic, so our solution opens the possibility to use multiple hard drives to scale beyond a single disk. In the future, this could enable archive node operators to use a small SSD with excellent performance to store the most recent blocks, while storing older blocks on a larger, less expensive disk.
Archive Node Storage Optimisations
In the following, we'll explain how and why the new archive node storage was divided into multiple volumes:
- The
uppervolume contains the most recent history and is identical to the store used by a rolling node. This volume stores everything necessary to participate in endorsements and the Tezos consensus algorithm. - The
lowervolumes are separate folders that store older blocks to preserve the blockchain's integrity and respond to RPC requests.
When Octez interacts with the store, Irmin transparently directs reads and writes to the correct volume, which has the same API as before. New public APIs added in Irmin 3.7 allow Octez to configure the lower volumes directory and to create new lower volumes dynamically.
An important consideration is that each volume is self-contained:
- Reading recent history and adding new blocks will only interact with the
uppervolume, with no need to consult the lower volumes at all. This implies that archive nodes will perform exactly the same operation and access the same data layout as if one was running as a rolling node. - Reading information about an old block, and recursively all of its children's objects, will only perform reads from one specific
lowervolume pertaining to that block. As an example, it means that an RPC request to read a block will interact only with a single volume.
In other words, data locality is enforced and random reads are bounded to a much smaller region (proportional to the size of the volumes where the operation takes place).
To achieve these self-contained volumes, a bit of data duplication is required. This is where the Irmin GC compaction algorithm intervenes! Each volume contains a small summary of the old data required for self-containment. Thanks to this summary, complex reads can avoid visiting other lower volumes since the required data can be found locally. This has two benefits:
- This data summary is compacted. Previously, archive nodes performance suffered from random reads into an enormous data file, which caused them to be slower than rolling nodes. With the new
uppervolume, archive nodes will be able to perform those expensive reads from the compact summary -- in the exact same way as rolling nodes already do. - As long as configured paths are preserved, each
upperandlowervolume can be stored on different disks. The initial Octez integration will not expose these capabilities directly, but as the blockchain history continues to grow, this feature will provide flexibility for the capabilities that Octez provides for archive node operators.
Furthermore, the GC compaction algorithm is also applied to the lower volumes data. The Tezos blockchain can contain temporary forks that will be abandoned later. While those blocks are important in the upper volume until consensus has been reached, they can safely be removed when data is transferred to a lower volume. This saves disk space and cleans up the blockchain from unused blocks.
The following graphs show the performances of the new archive nodes compared to the existing fast rolling nodes. We replay the Tezos blockchain trace, performing all operations as fast as possible (in the same way it happened, only without network interference). By recording the disk space used by the two nodes over time, we can observe how fast they can process and store new blocks on disk:
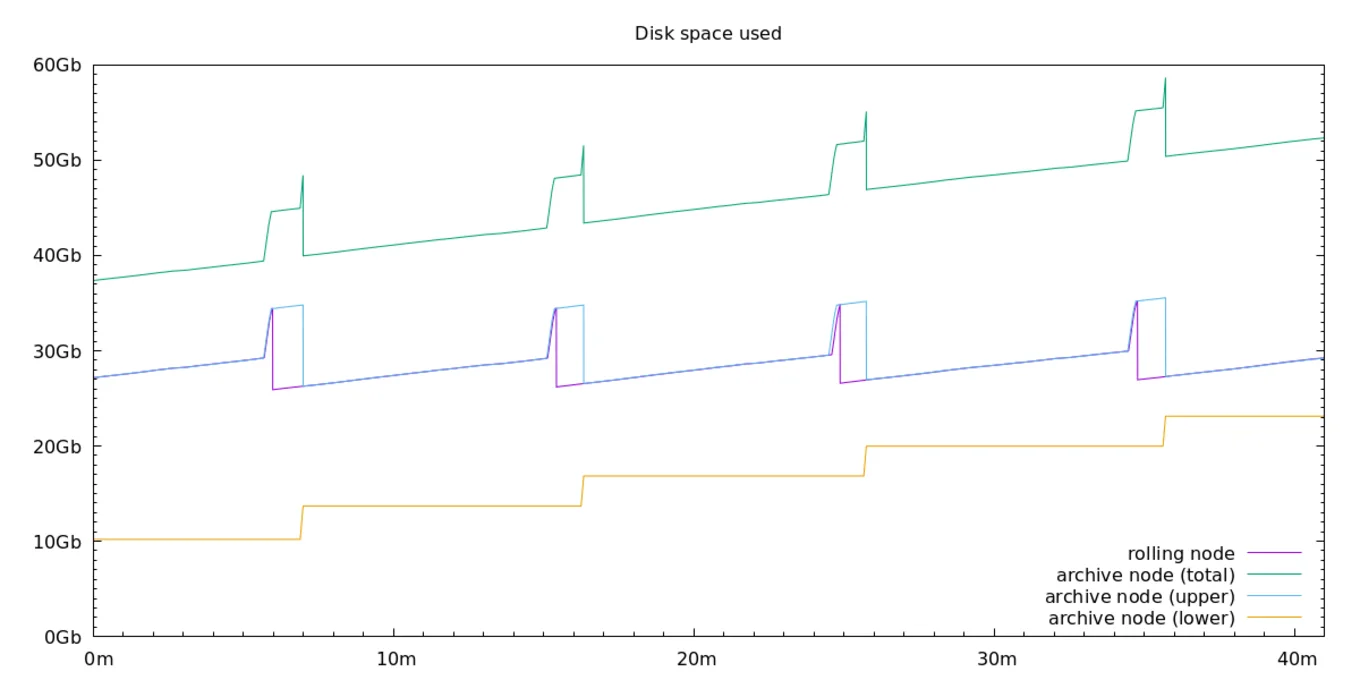
The purple sawtooth wave of the rolling node disk usage corresponds to when the Irmin garbage collector visits the upper volume to release old blocks and free disk space. In production, this happens at the end of every Tezos cycles.
In the case of archive nodes, this old data will not be deleted. Instead, it will be transferred and compacted to the lower volume (in yellow). This results in an increasing total disk space (in green) as the blockchain grows. The blue line shows that the data transfer can take a few minutes (depending on the hard drive that stores the lower volume)! But as this data transfer is done in a background process, the new archive node is able to keep up with the fast rolling node performance like clockwork. The graph confirms this assertion, as the upper disk space used by the archive node (in blue) is same as the disk space used by the rolling node (in purple). This means that both nodes were able to process new blocks at the same speed.
This is not a big surprise, since archive nodes are running the same code as a rolling node in their upper volume. In fact, one could imagine deleting the lower archived volumes, and the archive node would keep working as a rolling node! (Well, almost! We have a security in place to detect that an archive node was incorrectly configured and has lost parts of its history, which could happen if the lower volumes are moved to a different disk.)
Looking at the nodes' memory usage, we can see that the tradeoff for using the efficient upper volume optimisation in archive nodes is that they must now run the Irmin garbage collector. The GC requires some extra RAM while it runs, causing spikes in memory usage:
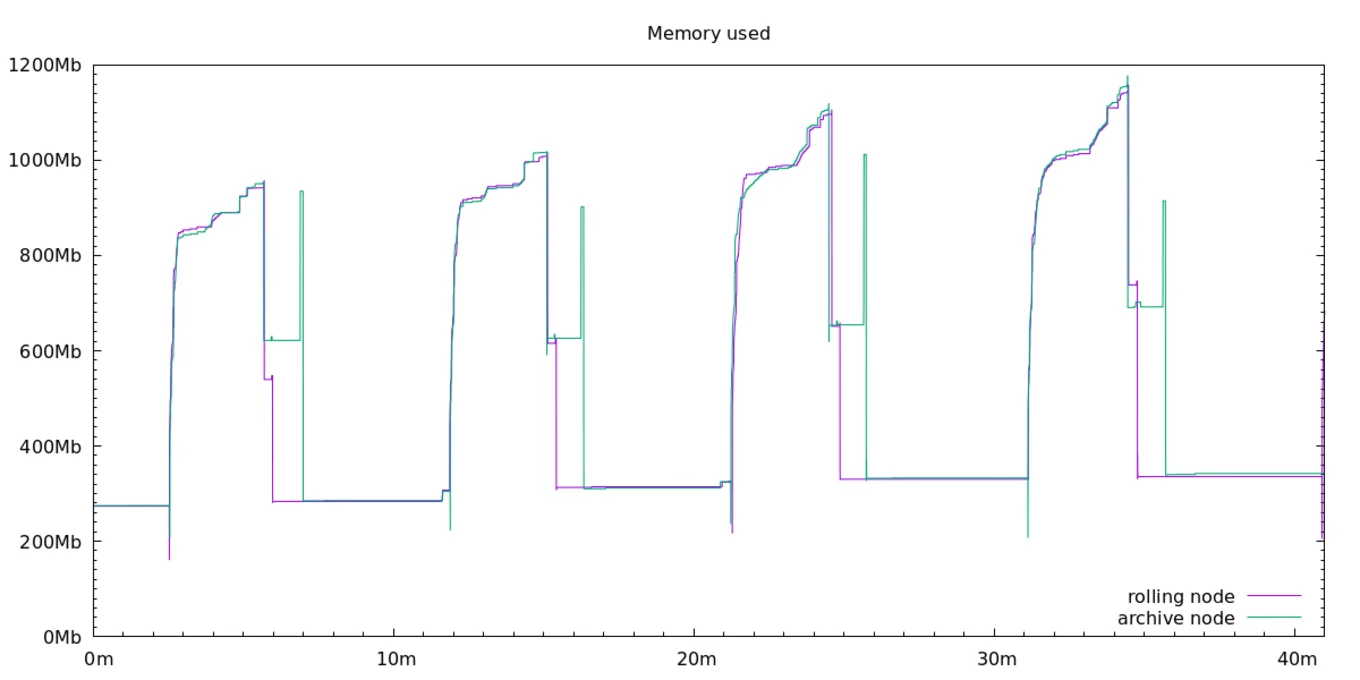
Otherwise the analysis of the memory graph is the same. The GC context pruning terminates a bit earlier for rolling nodes, as archive nodes have to go through the additional step of compacting old data and transferring it to the lower volume (while rolling nodes just delete it). Once again, we get a confirmation that this extra work does not impact the archive node's performance. Rather, it keeps processing new blocks as fast as a rolling node! Both nodes reach the end of the cycles at the same time, triggering the next GC memory spike.
While the integration of these features into Octez is still in-progress, early results show a noticeable decrease in bootstrapping time (by ~30%!) for an archive node when it is using lower volumes versus when it is not. These results need further verification, but they demonstrate some of the potential expected performance improvements for archive nodes.
Other Optimisations in Irmin 3.5, 3.6, and 3.7
Behind the scenes, further optimisations of Octez context pruning have been introduced. They provide benefits to both the existing rolling nodes and the new archive node volumes.
First in Irmin 3.5, we fixed the garbage collector to bound the amount of disk space required to perform a context pruning:
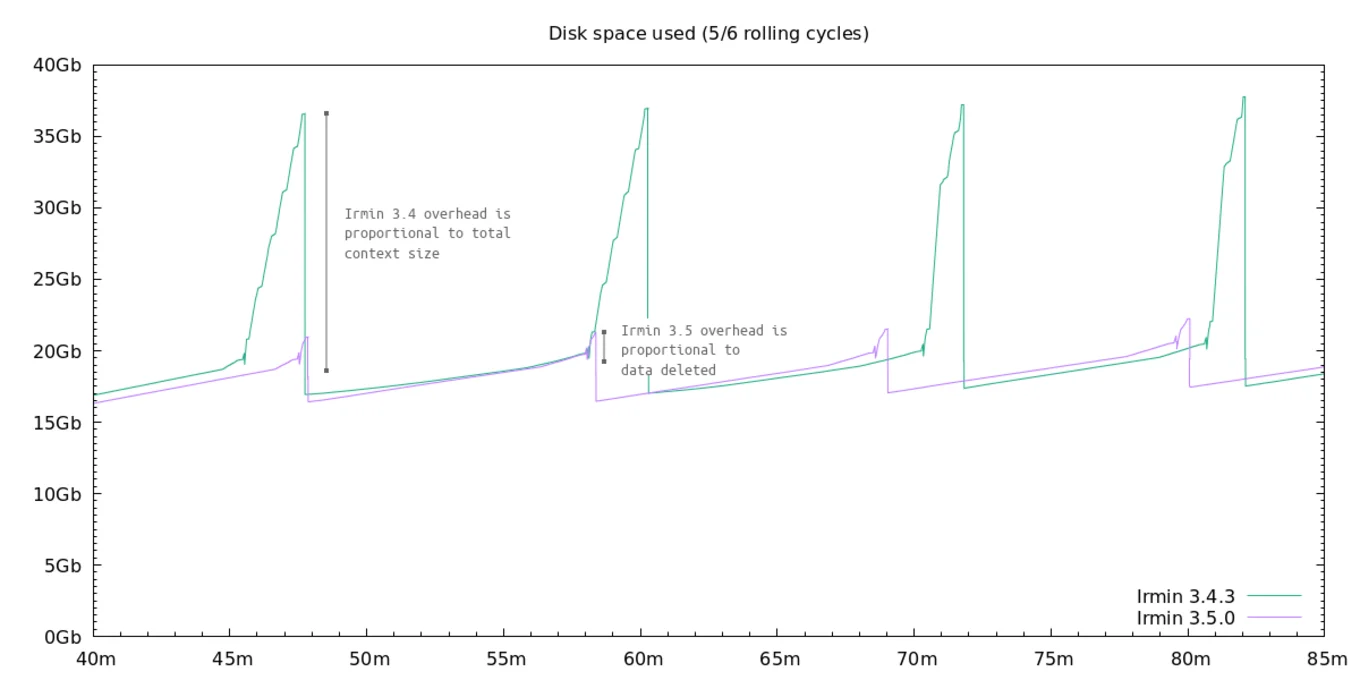
This has already been made available in Octez v16 with the release of Irmin 3.5 in December 2022.
In Irmin 3.6, the compaction algorithm was optimised to traverse the blockchain in disk order. Reducing random accesses yields a faster context pruning duration and lower the memory requirements by half during GC. The memory graph below shows the improvements, both in the height and width of the spikes induced by the GC, with Irmin 3.5 in green and Irmin 3.6 in orange:
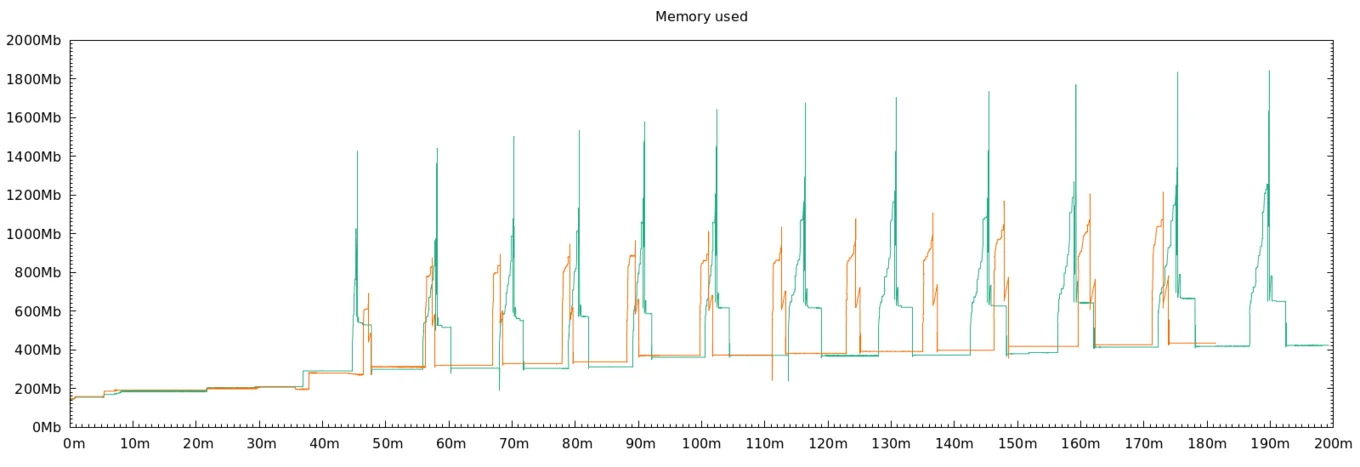
Finally in Irmin 3.7, the summary produced by the compaction algorithm and present in each upper and lower volumes was optimised for reading speed. As this summary is accessed often, we can see from the trace replay that operations start to perform faster once the compacted summary is available, right after the first GC:
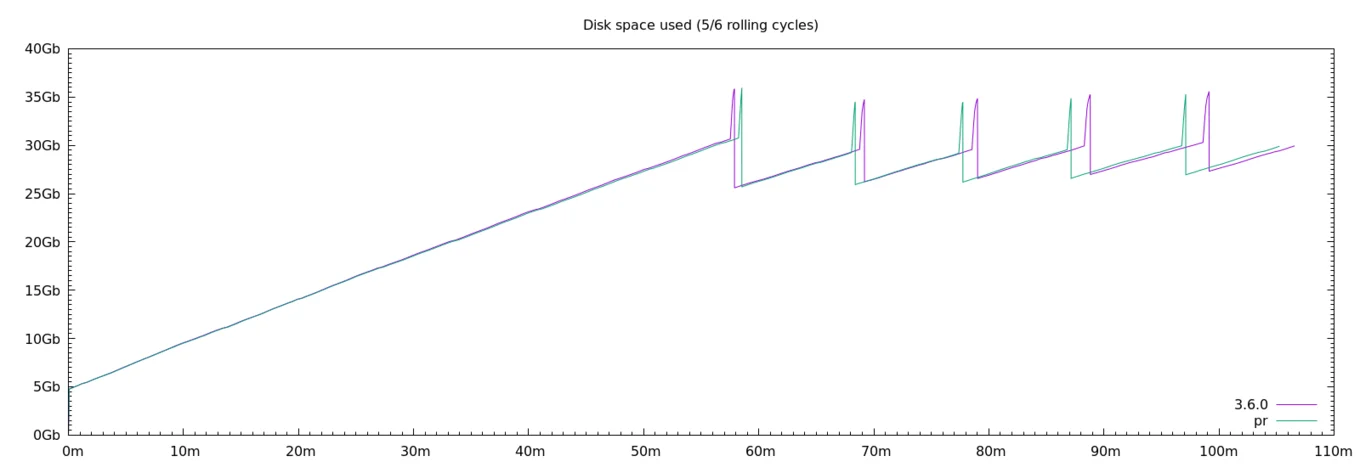
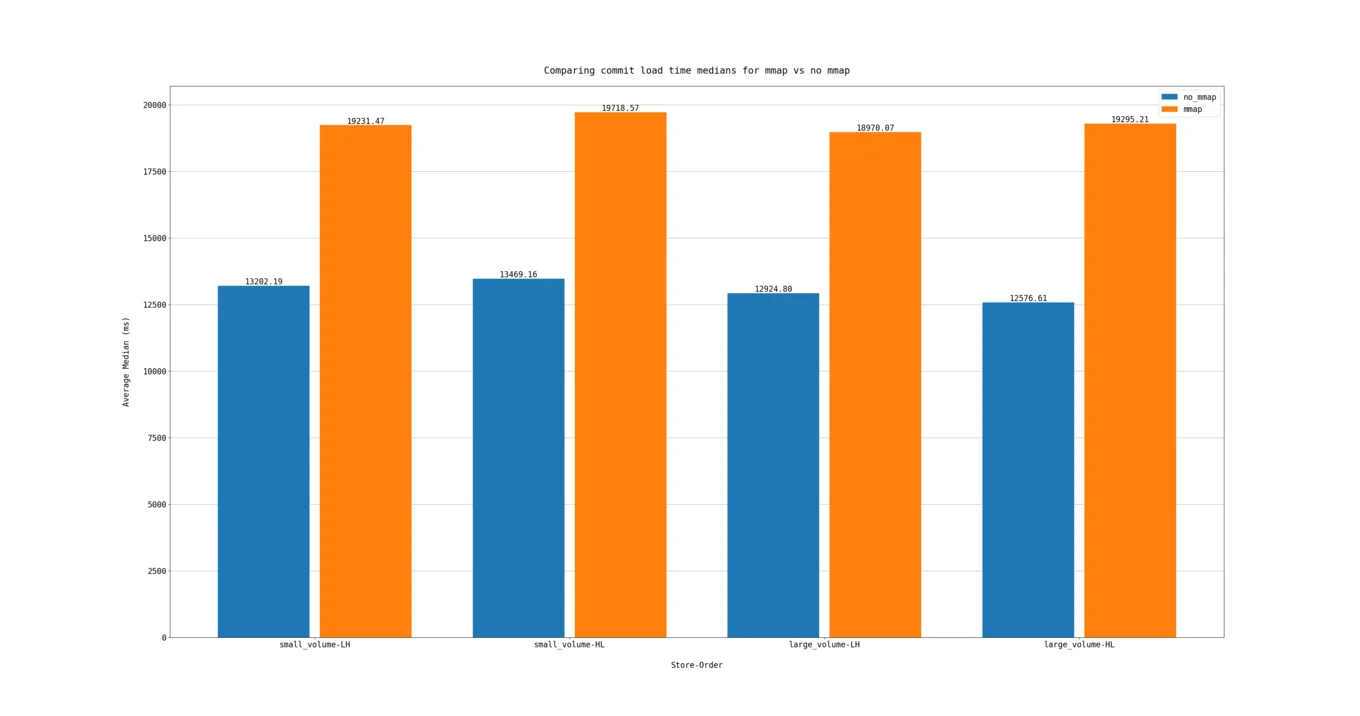
A read intensive benchmark shows the performance boost on different read patterns and volume sizes:
Conclusion
The Irmin 3.5 and 3.6 releases brought much needed disk and memory optimisations to Octez context pruning for rolling nodes. The Irmin 3.7 release brings more improvements to rolling nodes and introduces the same optimised garbage collection design to archive nodes, allowing them to have the same small and efficient store for recent history and enabling future improvements for storing history on multiple disks. Integration of Irmin 3.7's features into Octez is in-progress and will ship in a future version of Octez. In the meantime, we welcome your comments and feedback on the optimisations and design choices. Join the conversation on the OCaml Discuss forum, in the GitHub Issues, and through comments on the Tezos Agora post.
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.