
Lightning Fast with Irmin: Tezos Storage is 6x faster with 1000 TPS surpassed
Over the last year, the Tarides storage team has been focused on scaling the storage layer of Octez, the most popular node implementation for the Tezos blockchain. With the upcoming release of Octez v13, we are reaching our performance goal of supporting one thousand transactions per second (TPS) in the storage layer! This is a 6x improvement over Octez 10. Even better, this release also makes the storage layer orders of magnitude more stable, with a 12x improvement in the mean latency of operations. At the same time, we reduced the memory usage by 80%. Now Octez requires a mere 400 MB of RAM to bootstrap nodes!
In this post, we'll explain how we achieved these milestones thanks to Irmin 3, the new major release of the MirageOS-compatible storage layer developed and maintained by Tarides and used by Tezos. We'll also explain what this means for the Tezos community now and in the future.
As explained by a recent post on Nomadic Labs blog, there are various ways to evaluate the throughput of Tezos. Our purpose is to optimise the Tezos storage and identify and fix bottlenecks. Thus, our benchmarking setup replays actual data (the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet, corresponding to the period Dec 2021 – Jan 2022) and explicitly excludes the networking I/O operations and protocol computations to focus on the context I/O operations only. Thanks to this setup we managed to identify, fix, and verify that we removed the main I/O bottlenecks present in Octez:
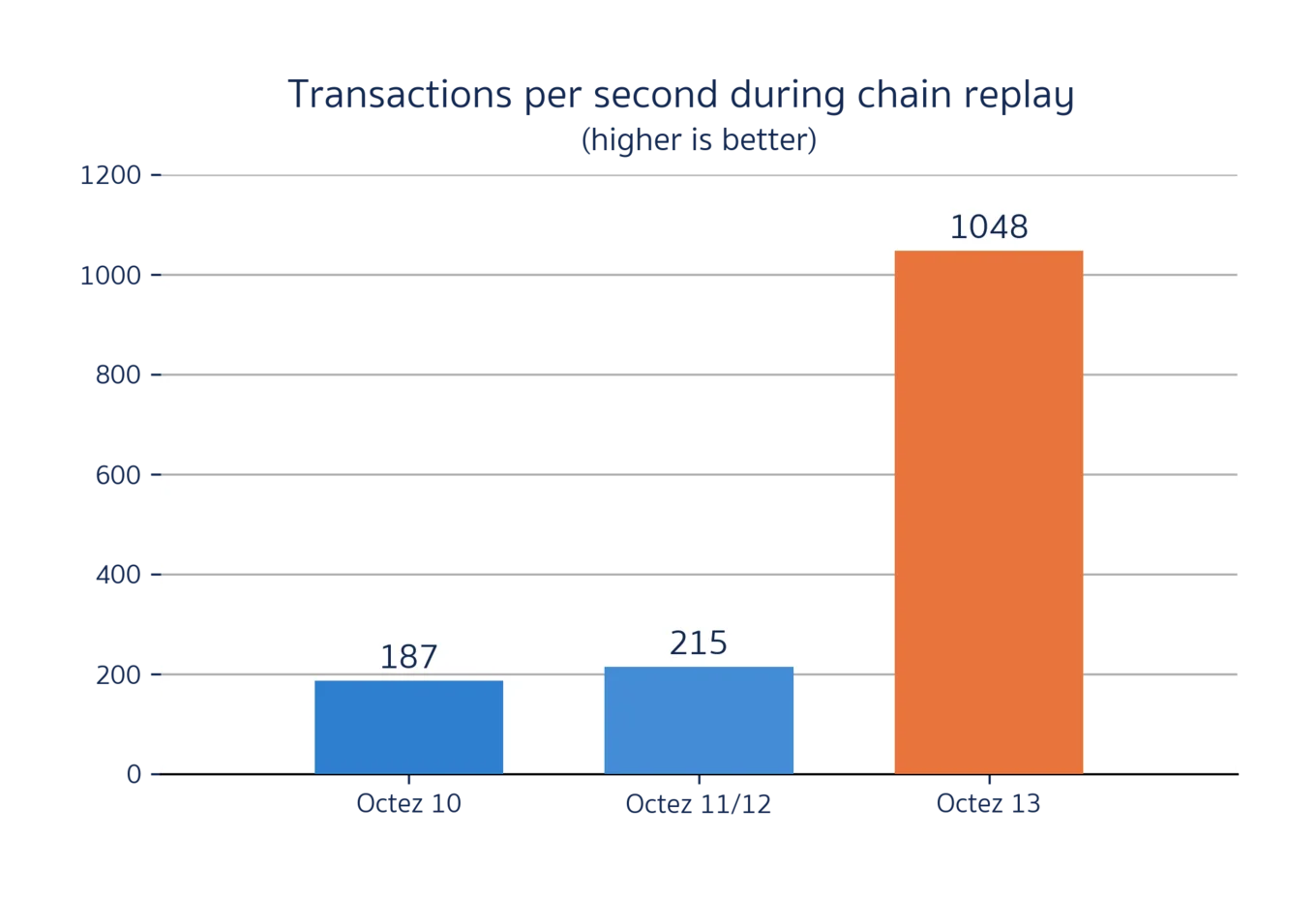
Comparison of the Transactions Per Second (TPS) performance between Octez 10, 11, 12 and 13 while replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet[1]. Octez 13 reaches 1043 TPS on average which is a 6x improvement over Octez 10.
Merkle databases: to index or not to index
A Tezos node keeps track of the blockchain state in a database called the context. For each block observed by the node, the context stores a corresponding tree that witnesses the state of the chain at that block.
Each leaf in the tree contains some data (e.g., the balance of a particular wallet) which has a unique hash. Together these leaf hashes uniquely determine the hashes of their parent nodes all the way up to the root hash of the tree. In the other direction – moving down the tree from the root – these hashes form addresses that allow each node to later be recovered from disk. In the Octez node, the context is implemented using Irmin, an open-source OCaml library that solves exactly this problem: storing trees of data in which each node is addressed by its hash.
As with any database, a crucial aspect of Irmin's implementation is its index, the component that maps addresses to data locations (in this case, mapping hashes to offsets within a large append-only data file). Indexing each object in the store by hash has some important advantages: for instance, it ensures that the database is totally deduplicated and enables fast random access to any object in the store, regardless of position in the tree.
As discussed in our irmin-pack post, the context index was
optimised for very fast reads at the cost of needing to perform an expensive
maintenance operation at regular intervals. This design was very effective in
the early months of the Tezos chain, but our recent work on benchmarking the
storage layer revealed two problems with it:
-
content-addressing bottlenecks transaction throughput. Using hashes as object addresses adds overhead to both reads and writes: each read requires consulting the index, and each write requires adding a new entry to it. At the current block rate and block size in Tezos Mainnet, these overheads are not a limiting factor, but this will change as the protocol and shell become faster. Our overall goal is to support a future network throughput of 1000 transactions per second, and doing this required rethinking our reliance on the index.
-
maintaining a large index impacts the stability of the node. The larger the index becomes, the longer it takes to perform regular maintenance operations on it. For sufficiently large contexts (i.e., on archive nodes), the store may be unable to perform this maintenance quickly enough, leading to long pauses as the node waits for service from the storage layer. In the context of Tezos, this can lead to users occasionally exceeding the maximum time allowed for baking or endorsing a block, losing out on the associated rewards.
Over the last few months, the storage team at Tarides has been hard at work addressing these issues by switching to a minimal indexing strategy in the context. This feature is now ready to ship, and we are delighted to present the results!
Consistently fast transactions: surpassing the 1000 TPS threshold
The latest release of Irmin ships with a new core feature that enables object addresses that are not hashes. This feature unlocks many future optimisations for the Octez context, including things like automatic inlining and layered storage. Crucially, it has allowed us to switch to using direct pointers between internal objects in the Octez context, eliminating the need to index such objects entirely! This has two immediate benefits:
-
read operations no longer need to search the index, improving the overall speed of the storage considerably;
-
the index can be shrunk by a factor of 360 (from 21G to 59MB in our tests!). We now only need to index commit objects in order to be able to recover the root tree for a given block at runtime. This "minimal" indexing strategy results in indices that fit comfortably in memory and don't need costly maintenance. As of Octez 13, minimal indexing is now the default node behaviour[2].
So what is the performance impact of this change? As detailed in our recent post on replay benchmarking, we were able to isolate and measure the consequences of this change by "replaying" a previously-recorded trace of chain activity against the newly-improved storage layer. This process simulates a node that is bottlenecked purely by the storage layer, allowing us to assess its limits independently of the other components of the shell.
For these benchmarks, we used a replay trace containing the first 150,000 blocks of the Hangzhou Protocol deployment on Tezos Mainnet (corresponding to the period December 2021 – January 2022)[3].
One of the most important metrics collected by our benchmarks is overall throughput, measured in transactions processed per second (TPS). In this context, a "transaction" is an individual state transition within a particular block (e.g., a balance transfer or a smart contract activation). We queried the TzStats API in order to determine the number of transactions in each block and thus, our measured transaction throughput. As shown in the graph above, doing this for the last few releases of Octez reveals that storage TPS has skyrocketted from ~200 in Octez 12 to more than 1000 in Octez 13! 🚀
As a direct consequence, the total time necessary to replay our Hangzhou trace on the storage layer has decreased from ~1 day to ~4 hours. We're nearly 6 times faster than before!
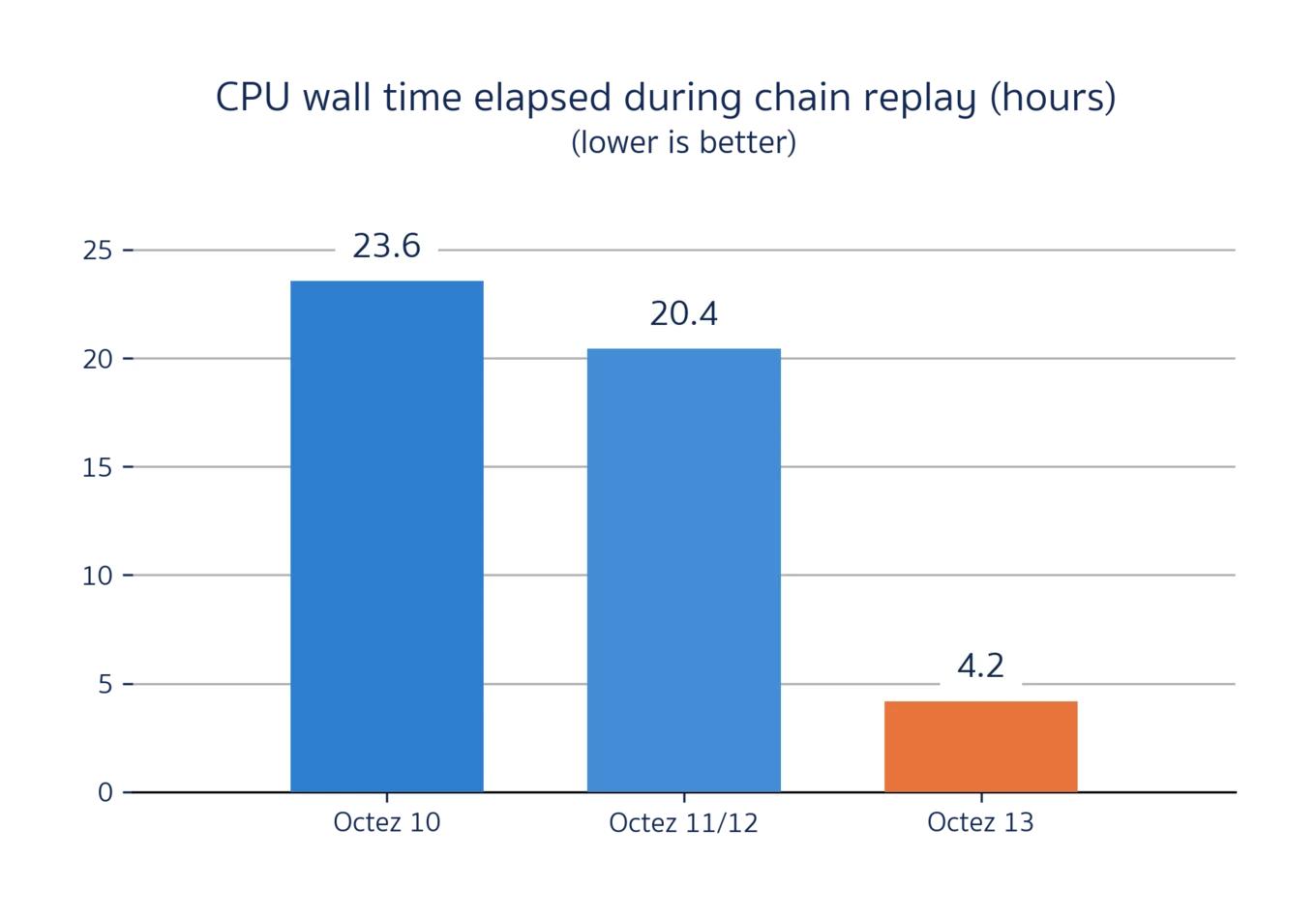
Comparison of CPU time elapsed between Octez 10, 11, 12, and 13 while replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet[1]. While Octez 10 took 1 day to complete the replay, Octez 13 only takes 4 hours and is nearly 6 times faster than before!
Overall throughput is not the only important metric, however. It's also important that the variance of storage performance is kept to a minimum, to ensure that unrelated tasks such as endorsement can be completed promptly. To see the impact of this, we can inspect how the total block time varies throughout the replay:
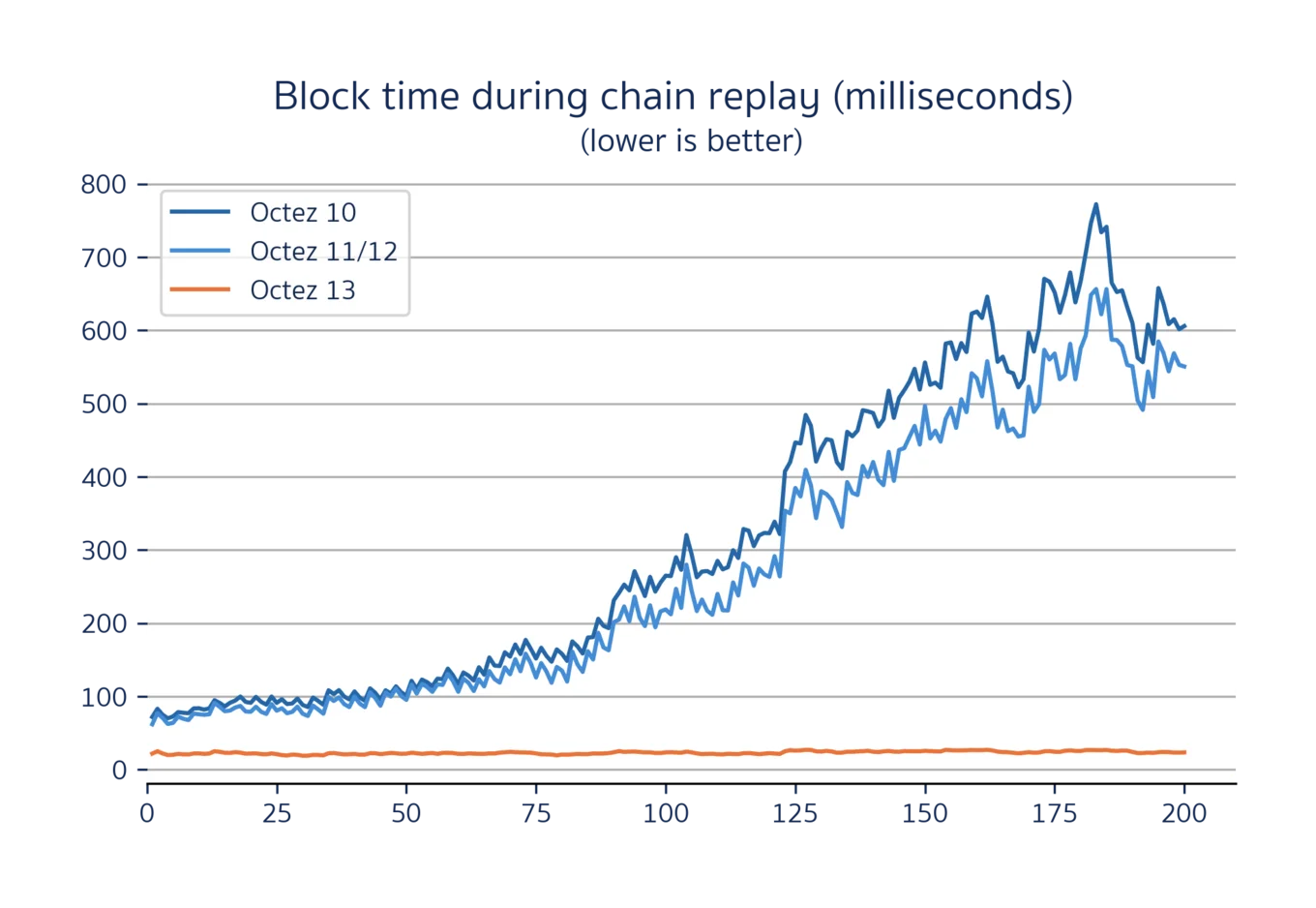
Comparison of block time latencies between Octez 10, 11, 12, and 13 while replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet[1]. Octez 13's mean block validation time is 23.2 ± 2.0 milliseconds while Octez v10 was down from 274 ± 183 milliseconds (and a worst-case peak of 800 milliseconds!). This 12x improvement in opearation's mean latency leads to much more consistent endorsement rights for bakers.
Another performance metric that has a big impact on node maintainers is the maximum memory usage of the node, since this sets a lower bound on the hardware that can run Octez. Tezos prides itself on being deployable to very resource-constrained hardware (such as the Raspberry Pi), so this continues to be a focus for us. Thanks to the reduced index size, Octez 13 greatly reduces the memory requirements of the storage layer:
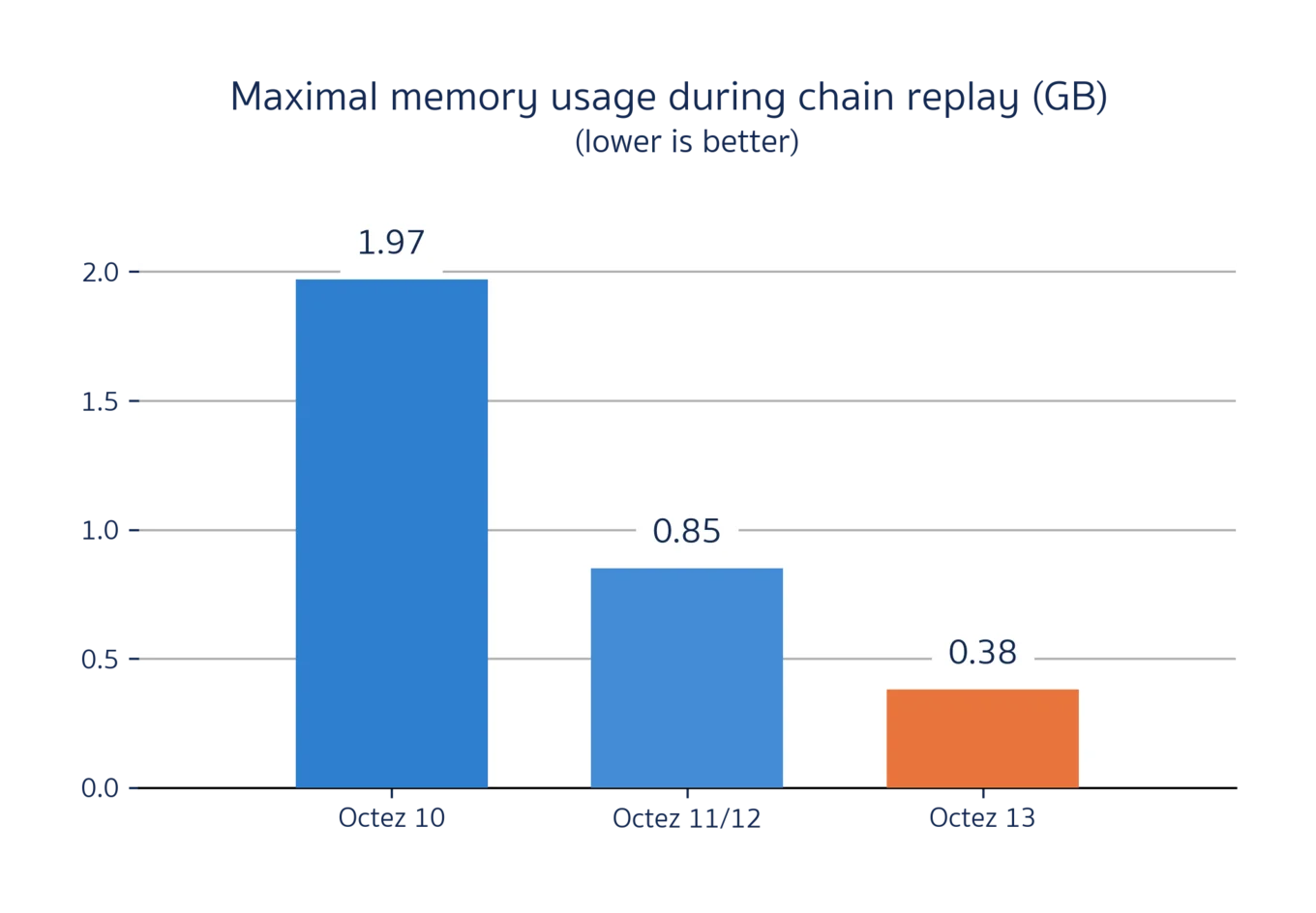
Comparison of maximal memory usage (as reported by
getrusage(2)) between Octez 10, 11, 12, and 13 while replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet[1]. The peak memory usage is x5 less in the Octez 13 storage layer compared to Octez 10**, owing to the significantly reduced size of the index. 400 MB of RAM is now enough to bootstrap Octez 13!
Finally, without an index the context store can no longer guarantee to have perfect object deduplication. Our tests and benchmarks show that this choice has relatively little impact on the context size as a whole, particularly since it no longer needs to store an index entry for every object!
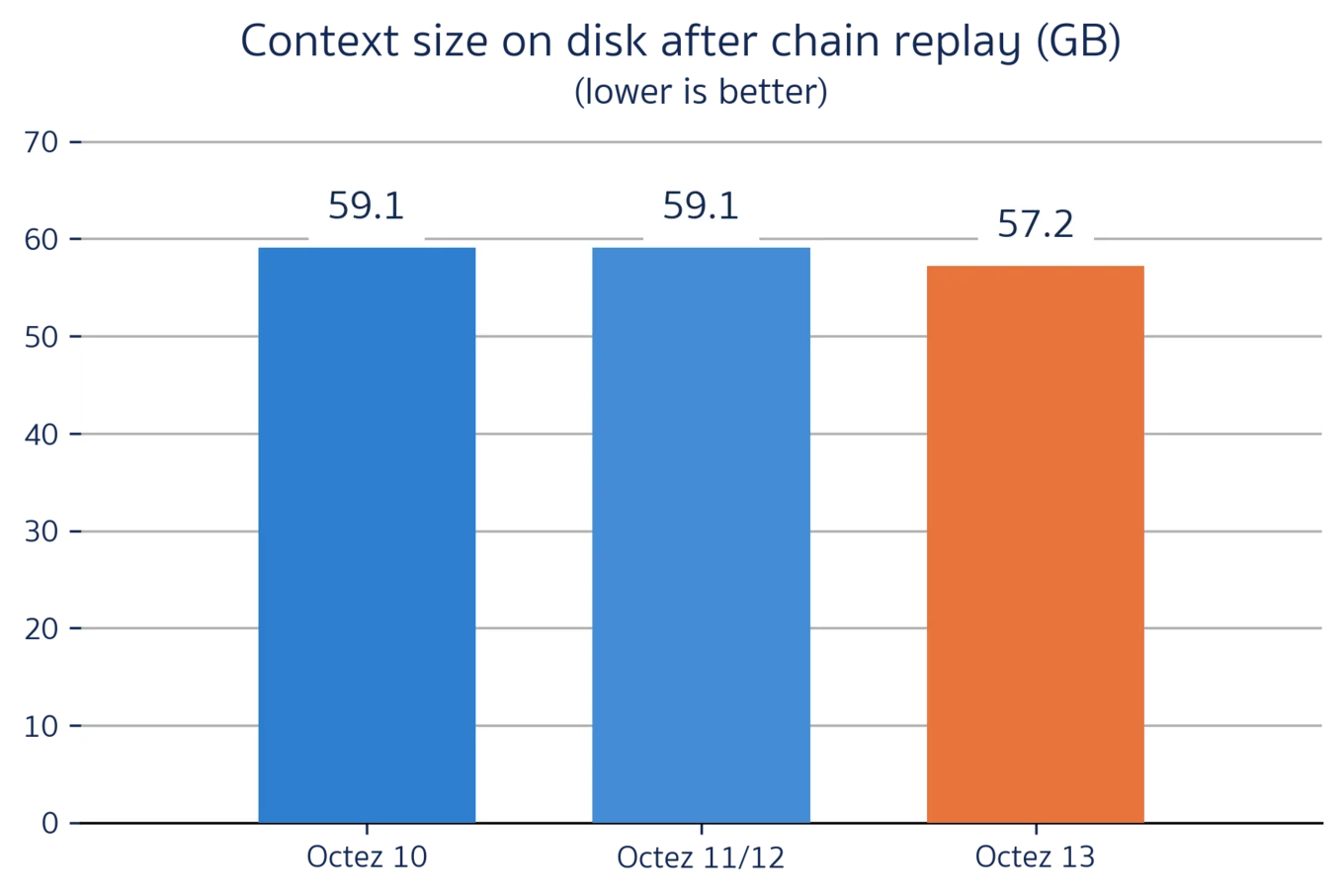
Comparison of storage size between Octez 10, 11, 12, and 13 while replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet[1]. Octez 13's uses similar disk resources than previous versions: the duplicated data is fully compensated by the reduced indexed size.
What this means for users of the Octez shell:
- The general I/O performance of the storage layer is vastly improved, as the storage operations are 6 times faster and a have 12 times lower mean latency while the memory usage is divided by 5.
- In particular, this mode eliminates the risk of losing baking rewards due to long index merges.
Migrating your Octez node to use the newer storage
Irmin 3 is included with Octez v13-rc1, which has just been released today. The storage format is fully backwards-compatible with Octez 12, and no migration process is required to upgrade.
Newly-written data after the shell upgrade will automatically benefit from the new, direct internal pointers, and existing data will continue being read as before. Performing a bootstrap (or importing a snapshot) with Octez 13 will build a context containing only direct pointers. Node operators should upgrade as soon as possible to benefit.
The future of the Octez storage layer
Irmin 3 is just the beginning of what the Tarides storage team has in store for 2022. Our next focus is on implementing the next iteration of the layered store, a garbage collection strategy for rolling nodes. Once this has landed, we will collaborate with the Tarides Multicore Applications team to help migrate Octez to using the newly-merged Multicore OCaml.
If this work sounds interesting, the Irmin team at Tarides is currently hiring!
Thanks for reading, and stay tuned for future updates from the Irmin team!
-
Our benchmarks compare Octez 10.2, 11.1, 12.0, and 13.0-rc1 by replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet (corresponding to the period Dec 2021 – Jan 2022) on an Intel Xeon E-2278G processor constrained to use at most 8 GB RAM. Our benchmarking setup explicitly excludes the networking I/O operations and protocol computations to focus on the context I/O operations only. Octez 10.2 uses Irmin 2.7.2, while both Octez 11.1 and 12.0 use Irmin 2.9.1 (which explains why the graphs are similar). Octez v13-rc1 uses Irmin 3.2.1, which we just released this month (Apr 2022).
↩︎︎1↩︎︎2↩︎︎3↩︎︎4↩︎︎5 -
The trade-off here is that without an index the context store can no longer guarantee to have perfect deduplication, but our testing and benchmarks indicate that this has relatively little impact on the size of the context as a whole (particularly after accounting for no longer needing to store an index entry for every object!).
↩︎︎ -
To reproduce these benchmarks, you can download the replay trace we used here (14G). This trace can be replayed against a fork of
↩︎︎lib_contextavailable here.
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.