
Towards Minimal Disk-Usage for Tezos Bakers
Over the last few months, Tarides has focused on designing, prototyping, and integrating a new feature for Tezos bakers: automatic context pruning for rolling and full nodes. This feature will allow bakers to run Tezos with minimal disk usage while continuing to enjoy 12x more responsive operations. The first version has been released with Octez v15. The complete, more optimised context pruning feature will come with Octez v16. We encourage every Tezos baker to upgrade and give feedback.
We have implemented context pruning for rolling and full nodes, which requires ~35GB of disk for storing 6 cycles in the upper layer. In Octez v15, each subsequent pruning run needs an additional 40GB, but that space is recovered when the operation finishes. We plan to remove that extra requirement in Octez v16.
Improve Space Usage with Context Pruning
The [Tezos context] is a versioned key/value store that associates for each block a view of its ledger state. The versioning uses concepts similar to Git. The current implementation is using irmin as backend and abstracted by the lib_context library.
We have been designing, prototyping, and integrating a new structure for Irmin storage. It is now reorganised into two layers: one upper layer that contains the latest cycles of the blockchain, which are still in use, and a lower layer containing older, frozen data. A new garbage collection feature (GC) periodically restructures the Tezos context by removing unused data in the oldest cycles from the upper layer, where only the data still accessible from the currently live cycles are preserved. The first version of the GC, available in Octez-v15, is optimised for rolling and full nodes and thus does not contain a lower layer. We plan to extend this feature in Octez-v17 to dramatically improve the archive nodes' performance by moving the unused data to the lower layer (more on this below).
Garbage collection and subsequent compression of live data improves disk and kernel cache performance, which enhances overall node performance. Currently, rolling nodes operators must apply a manual cleanup process to release space on the disk by discarding unused data. The manual cleanup is tedious and error-prone. Operators could discard valuable data, have to stop their baker, or try to devise semi-automatic procedures and run multiple bakers to avoid downtime. The GC feature provides rolling nodes operators a fully automated method to clean up the unused data and guarantees that only the unused data is discarded, i.e., all currently used data is preserved.
The GC operation is performed asynchronously with minimal impact on the Tezos node. In the rolling node's case, a GC'd context uses less disk space and has a more stable performance throughout, as the protocol operations (such as executing smart contracts or computing baking rewards) only need data from the upper layer. As such, the nodes that benefit from the store's layered structure don't need to use the manual snapshot export/import—previously necessary when the disk’s context got too big. In the future, archive nodes’ performance will improve because only the upper layer is needed to validate recent blocks. This means archive nodes can bake as reliably as rolling nodes.
Tezos Storage, in a Nutshell
The Tezos blockchain uses Irmin as the main storage component. Irmin
is a library to design Git-like storage systems. It has many backends,
and one of them is irmin-pack, which is optimised for the Tezos use
case. In the followings, we focus on the main file used to store
object data: the store pack file.
Pack file: Tezos state is serialised as immutable functional objects.
These objects are marshalled in a append-only pack file, one after the
other. An object can contain pointers to the file's earlier (but not
later!) objects. Pointers to an earlier object are typically
represented by the offset (position) of the earlier object in the
pack file. The pack file is append-only: existing objects are
never updated.

An Irmin
packfile as a sequence of objects: | obj | obj | obj | ...
Commit objects: Some of the objects in the pack file are commit
objects. A commit, together with the objects reachable from that
commit, represents the state associated to a Tezos' block. The
Tezos node only needs the last commit to process new blocks, but
bakers will need a lot more commits to compute baking rewards.
Objects not reachable from these commits can are unreachable or dead
objects.
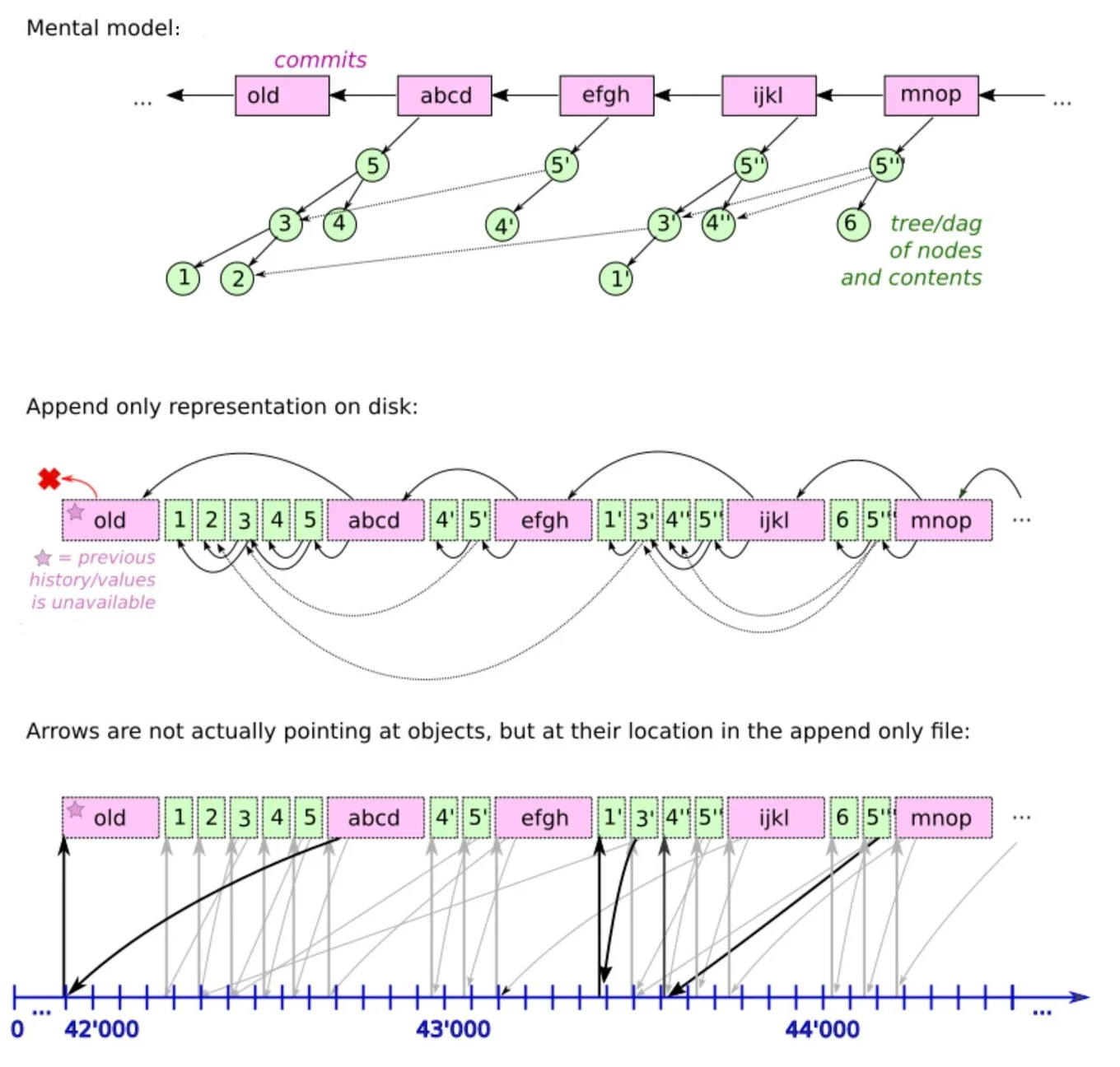
The data-structure (mental model) representation of the
packfile vs. its physical representation.
Archive nodes and rolling nodes: There are different types of Tezos nodes. An archive node stores the complete blockchain history from the genesis block. Currently, this is over 2 million blocks. Roughly speaking, a block corresponds to a commit. A rolling node stores only the last n blocks, where n is chosen to keep the total disk usage within some bounds. This may be as small as 5 (or even less) or as large as 40,000 or more. Another type of node is the "full node," which is between an archive node and a rolling node.
Rolling nodes, disk space usage: The purpose of the rolling node
is to keep resource usage, particularly disk space, bounded by only
storing the last blocks. However, the current implementation does
not achieve this aim. As rolling nodes execute, the pack file
grows larger and larger, and no old data is discarded. To get around
this problem, node operators periodically export snapshots of the
current blockchain state from the node, delete the old data,
and then import the snapshot state back.
Problem summary: The main problem we want to avoid is Tezos users
having to periodically export and import the blockchain state to
keep the disk usage of the Tezos node bounded. Instead, we want to
perform context pruning via automatic garbage collection of unreachable
objects. Periodically, a commit should be chosen as the GC
root, and objects constructed before the commit that are not
reachable from the commit should be considered dead branches, removed from
the pack store, and the disk space reclaimed. The problem is that
with the current implementation of the pack file, which is just an
ordinary file, it is impossible to "delete" regions corresponding to
dead objects and reclaim the space.
Automatised Garbage Collection Solution
Consider the following pack file, where the GC-commit object has
been selected as the commit root for garbage collection:
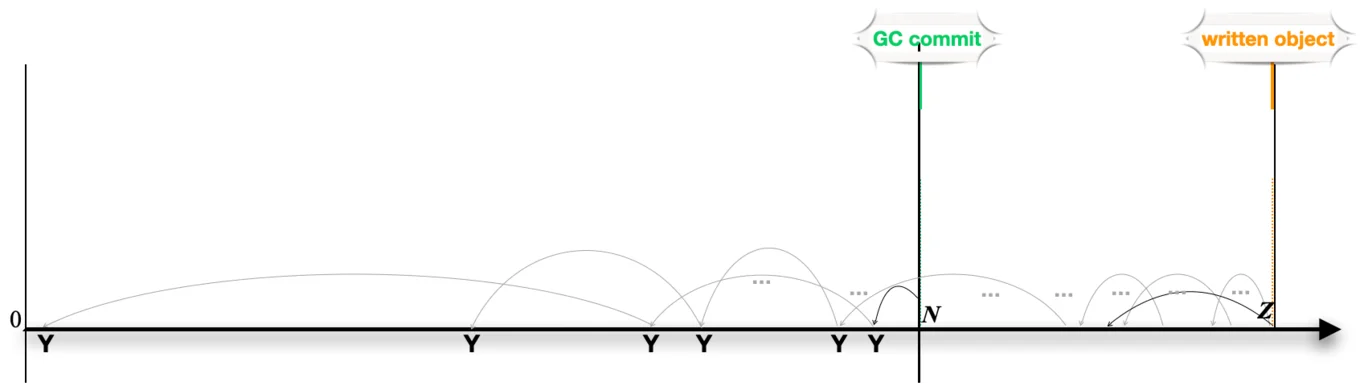
Objects that precede the commit root are either reachable from the
commit (by following object references from it) or not. For the
unreachable objects, we want to reclaim the disk space. For reachable
objects, we need to be able to continue to access them via their
offset in the pack file.
The straightforward solution is to implement the pack file using two
other data structures: the suffix and the prefix. The suffix
file contains the root commit object (GC-commit) and the live
objects represented by all bytes following the offset of GC-commit
in the pack file. The prefix file contains all the objects
reachable from the root commit, indexed by their offset. Note that the
reachable objects appear earlier in the pack file than the root
commit.
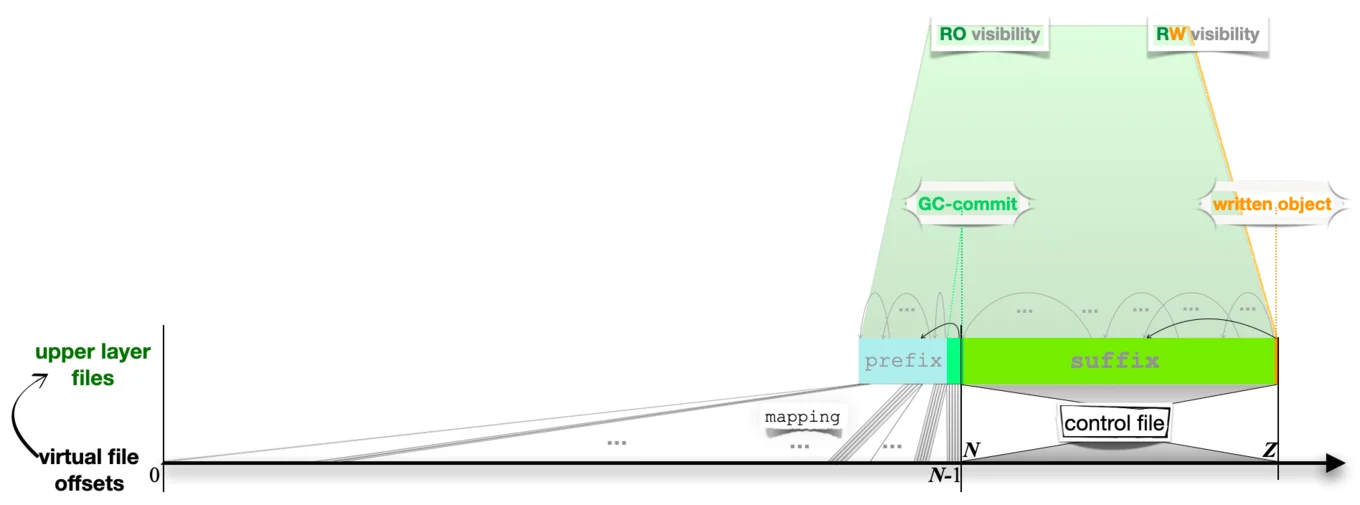
The layered structure of the
packfile withprefix+suffixas the upper layer.
Reading from the pack file is then simulated in an obvious way: if
the offset is for the GC-commit, or later, we read from the suffix
file, and otherwise, we lookup the offset in the prefix and return
the appropriate object. We only access the reachable objects in the
prefix via their offset. We replace the Irmin pack file with
these two data structures. Every time we perform garbage collection
from a given GC-commit, we create the next versions of the prefix
and suffix data-structures and switch from the current version to the next
version by deleting the old prefix and suffix to reclaim
disk space. Creating the next versions of the prefix and suffix
data-structures is potentially expensive. Hence, we implement these steps in a
separate process, the GC worker, with minimal impact on the running
Tezos node.
Caveat: Following Git, a commit will typically reference its parent commit, which will then reference its parent, and so on. Clearly, if we used these references to calculate object reachability, all objects would remain reachable forever. However, this is not what we want, so when calculating the set of reachable objects for a given commit, we ignore the references from a commit to its parent commit.
The prefix Data-Structure
The prefix is a persistent data-structure that implements a map from
the offsets in pack file to objects (the marshalled bytes
representing an object). In our scenario, the GC worker creates the
prefix, which is then read-only for the main process. Objects are
never mutated or deleted from the prefix file. In this setting, a
straightforward implementation of an object store suffices: we store
reachable objects in a data file and maintain a persistent (int → int) map from "offset in the original pack file" to "offset in the
prefix file."
Terminology: We introduce the term "virtual offset" for "offset in
the original pack file" and the term "real offset" for "offset in
the prefix file." Thus, the map outlining virtual offset to real
offset is made persistent as the mapping file.
Example: Consider the following, where the pack file contains
reachable objects o1 .. o10, (with virtual offsets v1 .. v10, respectively):
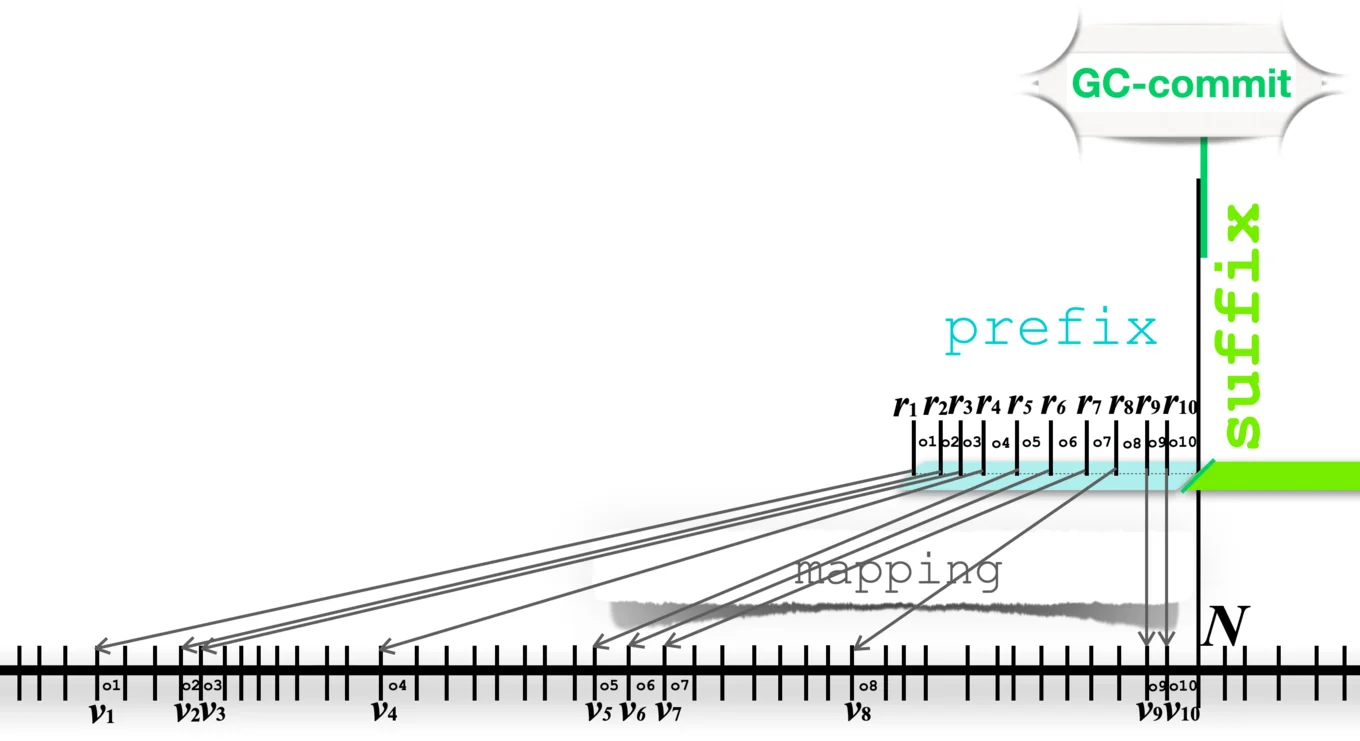
Note that the objects o1 .. o10 are scattered throughout the
pack file where they appear in ascending order (i.e., v1 < .. <
v10). The prefix file contains the same objects but with different
"real" offsets r1..r10, as now the objects o1 .. o10 appear one
after the other. The mapping needs to contain an entry (v1 → r1)
for object o1 (and similarly for the other objects) to relate the
virtual offset in the pack file with the real offset in the prefix
file.
To read from "virtual offset v3" (say), we use the map to retrieve
the real offset in the prefix file (i.e., r3) and then read the object
data from that position.
Asynchronous Implementation
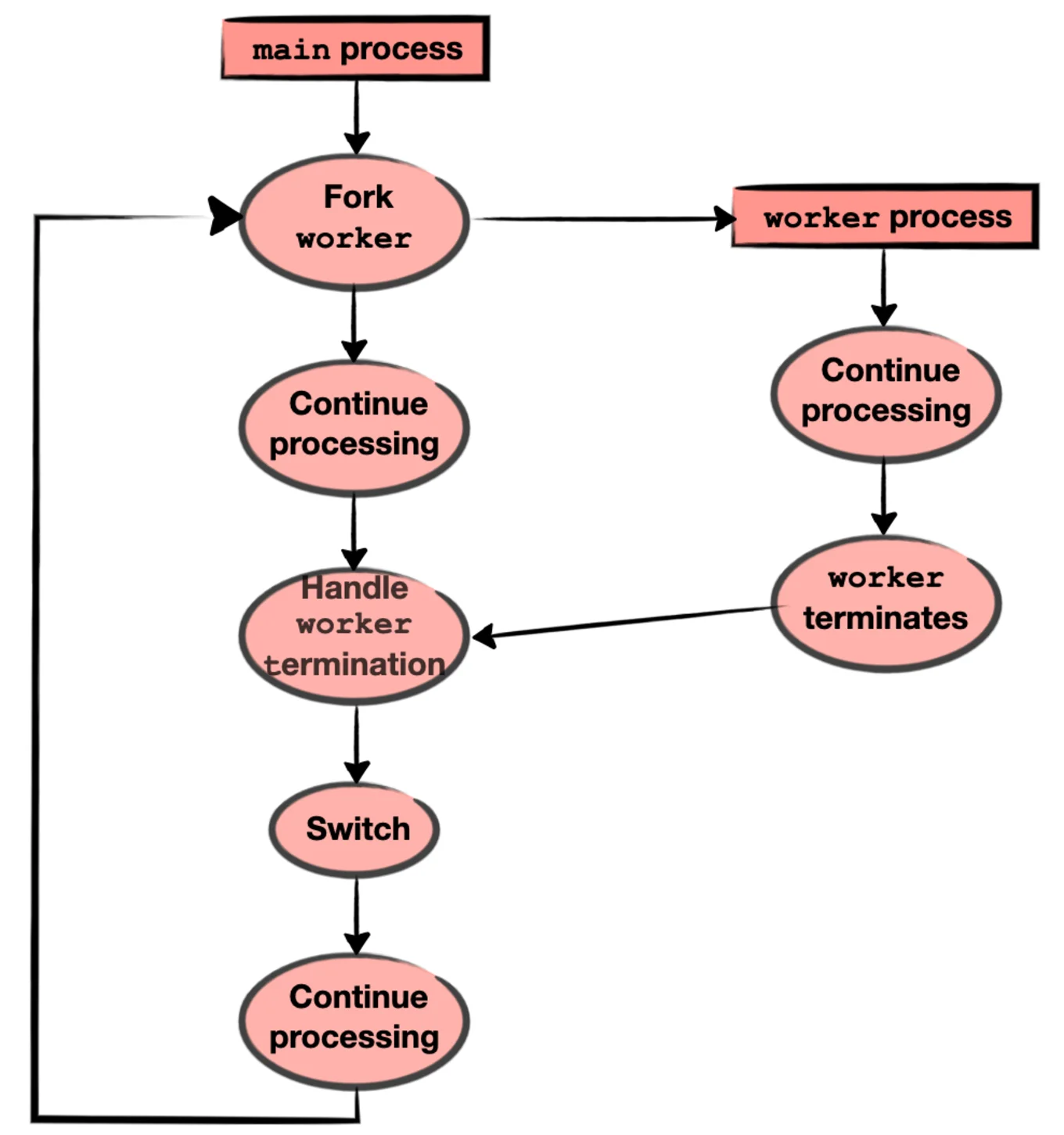
Tezos Context pruning is performed periodically. We want each round of
context pruning to take place asynchronously with minimal impact
on the main Tezos node. For this reason, when a commit is chosen as
the GC root, we fork a worker process to construct the next prefix
and suffix data structures. When the GC worker terminates, the main process
handles worker termination. It switches from the current
prefix+suffix to the next and continues operation. This
switch takes place almost instantaneously. The hard work is done in
the worker process as depicted next:
Read-only Tezos nodes: In addition to the main Tezos read/write
node that accesses the pack store, several read-only nodes also
access the pack store (and other Irmin data files) in read-only
mode. These must be synchronised when the switch is made from the
current prefix+suffix to the next prefix+suffix. This
synchronisation makes use of a (new) single control file.
Further Optimisations in the Octez Storage Layer
The context pruning via automatic garbage collection performs well and within the required constraints. However, it is possible to make further efficiency improvements. We next describe some potential optimisations we plan to work on over the next months.
Resource-aware garbage collection:
The GC worker intensively uses disk, memory, and OS resources. For example, the disk and memory are doubled in size during the asynchronous execution of the GC worker. We plan to improve on this by more intelligent use of resources. For example, computing the reachable objects during the GC involves accessing earlier objects, using a lot of random-access reads, with unpredictable latency. A more resource-aware usage of the file system ensures that the objects are visited (as much as possible) in the order of increased offset on disk. This takes advantage of the fact that sequential file access is much quicker and predictable than accessing the file randomly. The work on context pruning via a resource-aware garbage collection is planned to be included in Octez v16.
Retaining older objects for archive nodes:
Archive nodes contain the complete blockchain history, starting from
the genesis block. This results in a huge store pack file, many
times larger than the kernel’s page cache. Furthermore, live objects
are distributed throughout this huge file, which makes it difficult
for OS caching to work effectively. As a result, as the store becomes
larger, the archive node becomes slower.
In previous prototypes of the layered store, the design also included a
"lower" layer. For archive nodes, the lower layer contained all the
objects before the most recent GC-commit, whether they were reachable
or not. The lower layer was effectively the full segment of the
pack file before the GC commit root.
One possibility with the new layout introduced by the GC is to retain the
lower layer whilst still sticking with the prefix and mapping files
approach and preferentially reading from the prefix where
possible. The advantage (compared with just keeping the full pack
file) is that the prefix is a dense store of reachable objects,
improving OS disk caching and the snapshot export performance for
recent commits. In addition, the OS can preferentially cache the
prefix&mapping, which enhances general archive node performance
compared with trying to cache the huge pack file. As baking
operations only need to access these cached objects, their performance
will be more reliable and thus will reduce endorsement misses
drastically. However, some uses of the archive node, such as
responding to RPC requests concerning arbitrary blocks, would still
access the lower layer, so they will not benefit from this
optimisation. The work on improving performance for archive nodes is
planned for Octez v17.
Conclusion
With the context pruning feature integrated, Tezos rolling and full nodes accurately maintain all and only used storage data in a performant, compact, and efficient manner. Bakers will benefit from these changes in Octez v15, while the feature will be included in archive nodes in Octez v17.
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.