
Introducing irmin-pack

Senior Software Engineer
irmin-pack is an Irmin storage backend
that we developed over the last year specifically to meet the
Tezos use-case. Tezos nodes were initially using an
LMDB-based backend for their storage, which after only a year of activity led to
250 GB disk space usage, with a monthly growth of 25 GB. Our goal was to
dramatically reduce this disk space usage.
Part of the Irmin.2.0.0 release and still under active development, it has been successfully integrated as the storage layer of Tezos nodes and has been running in production for the last ten months with great results. It reduces disk usage by a factor of 10, while still ensuring similar performance and consistency guarantees in a memory-constrained and concurrent environment.
irmin-pack was presented along with Irmin v2 at the OCaml workshop 2020; you
can watch the presentation here:
General structure
irmin-pack exposes functors that allow the user to provide arbitrary low-level
modules for handling I/O, and provides a fast key-value store interface composed
of three components:
- The
packis used to store the data contained in the Irmin store, as blobs. - The
dictstores the paths where these blobs should live. - The
indexkeeps track of the blobs that are present in the repository by containing location information in thepack.
Each of these use both on-disk storage for persistence and concurrence and various in-memory caches for speed.
Storing the data in the pack file
The pack contains most of the data stored in this Irmin backend. It is an
append-only file containing the serialized data stored in the Irmin repository.
All three Irmin stores (see our architecture
page in the tutorial to learn more)
are contained in this single file.
Content and Commit serialization is straightforward through
Irmin.Type. They are written along with their length (to allow
correct reading) and hash (to enable integrity checks). The hash is used to
resolve internal links inside the pack when nodes are written.

Optimizing large nodes
Serializing nodes is not as simple as contents. In fact, nodes might contain an arbitrarily large number of children, and serializing them as a long list of references might harm performance, as that means loading and writing a large amount of data for each modification, no matter how small this modification might be. Similarly, browsing the tree means reading large blocks of data, even though only one child is needed.
For this reason, we implemented a Patricia Tree representation of internal nodes that allows us to split the child list into smaller parts that can be accessed and modified independently, while still being quickly available when needed. This reduces duplication of tree data in the Irmin store and improves disk access times.
Of course, we provide a custom hashing mechanism, so that hashing the nodes using this partitioning is still backwards-compatible for users who rely on hash information regardless of whether the node is split or not.
Optimizing internal references
In the Git model, all data are content-addressable (i.e. data are always
referenced by their hash). This naturally lends to indexing data by hashes on
the disk itself (i.e. the links from commits to nodes and from nodes to
nodes or contents are realized by hash).
We did not comply to this approach in irmin-pack, for at least two reasons:
-
Referencing by hash does not allow fast recovery of the children, since there is no way to find the relevant blob directly in the
packby providing the hash. We will go into the details of this later in this post. -
While hashes are being used as simple objects, their size is not negligible. The default hashing function in Irmin is BLAKE2B, which provides 32-byte digests.
Instead, our internal links in the pack file are concretized by the offsets –
int64 integers – of the children instead of their hash. Provided that the
trees are always written bottom-up (so that children already exist in the pack
when their parents are written), this solves both issues above. The data handled
by the backend is always immutable, and the file is append-only, ensuring that
the links can never be broken.
Of course, that encoding does not break the content-addressable property: one can always retrieve an arbitrary piece of data through its hash, but it allows internal links to avoid that indirection.
Deduplicating the path names through the dict
In fact, the most common operations when using irmin-pack consist of modifying
the tree's leaves rather then its shape. This is similar to the way most of us
use Git: modifying the contents of files is very frequent, while renaming or
adding new files is rather rare. Even still, when writing a node in a new
commit, that node must contain the path names of its children, which end up
being duplicated a large number of times.
The dict is used for deduplication of path names so that the pack file can
uniquely reference them using shorter identifiers. It is composed of an
in-memory bidirectional hash table, allowing to query from path to identifier
when serializing and referencing, and from identifier to path when deserializing
and dereferencing.
To ensure persistence of the data across multiple runs and in case of crashes,
the small size of the dict – less than 15 Mb in the Tezos use-case – allows
us to write the bindings to a write-only, append-only file that is fully read
and loaded on start-up.
We guarantee that the dict memory usage is bounded by providing a capacity
parameter. Adding a binding is guarded by this capacity, and will be inlined in
the pack file in case this limit has been reached. This scenario does not
happen during normal use of irmin-pack, but prevents attacks that would make
the memory grow in an unbounded way.
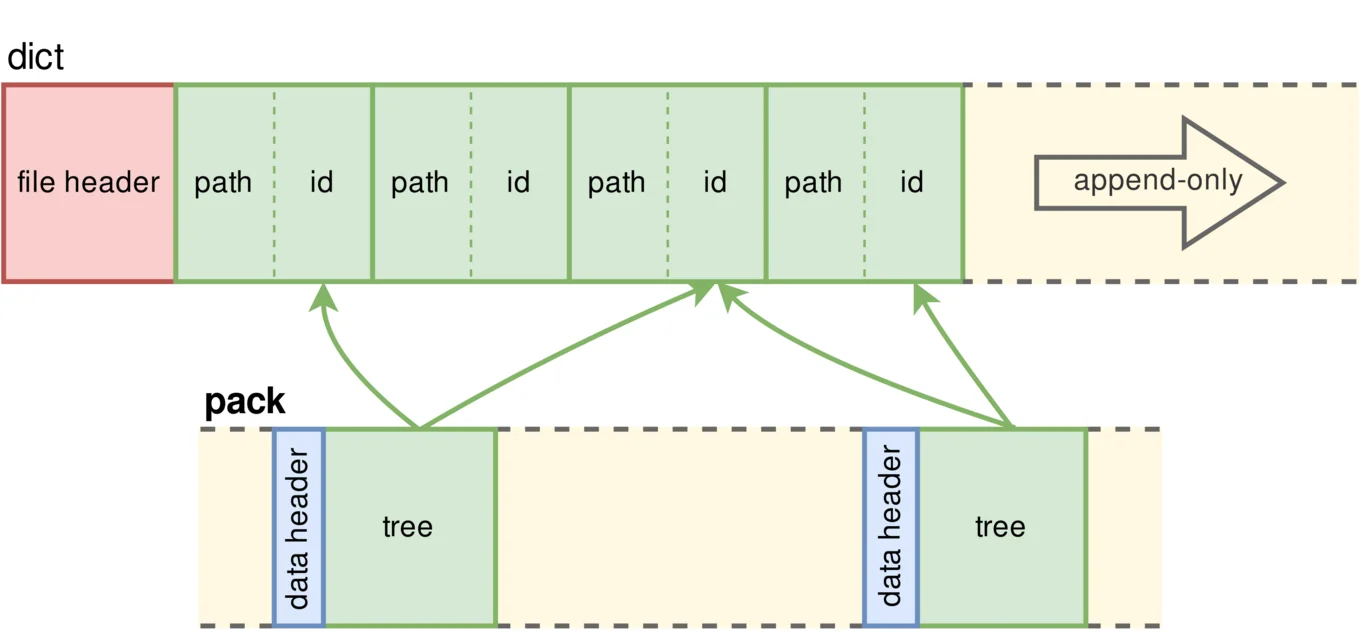
Retrieve the data in the pack by indexing
Since the pack file is append-only, naively reading its data would require a
linear search through the whole file for each lookup. Instead, we provide an
index that maps hashes of data blocks to their location in the pack file,
along with their length. This module allows quick recovery of the values queried
by hash.
It provides a simple key-value interface, that actually hides the most complex
part of irmin-pack.
type t
val v : readonly:bool -> path:string -> t
val find : t -> Key.t -> Value.t
val replace : t -> Key.t -> Value.t -> unit
(* ... *)
It has lead most of our efforts in the development of irmin-pack and is now
available as a separate library, wisely named index, that you can checkout on
GitHub under mirage/index and via opam as
the index and index-unix packages.
When index is used inside irmin-pack, the keys are the hashes of the data
stored in the backend, and the values are the (offset, length) pair that
indicates the location in the pack file. From now on in this post, we will
stick to the index abstraction: key and value will refer to the keys and
values as viewed by the index.
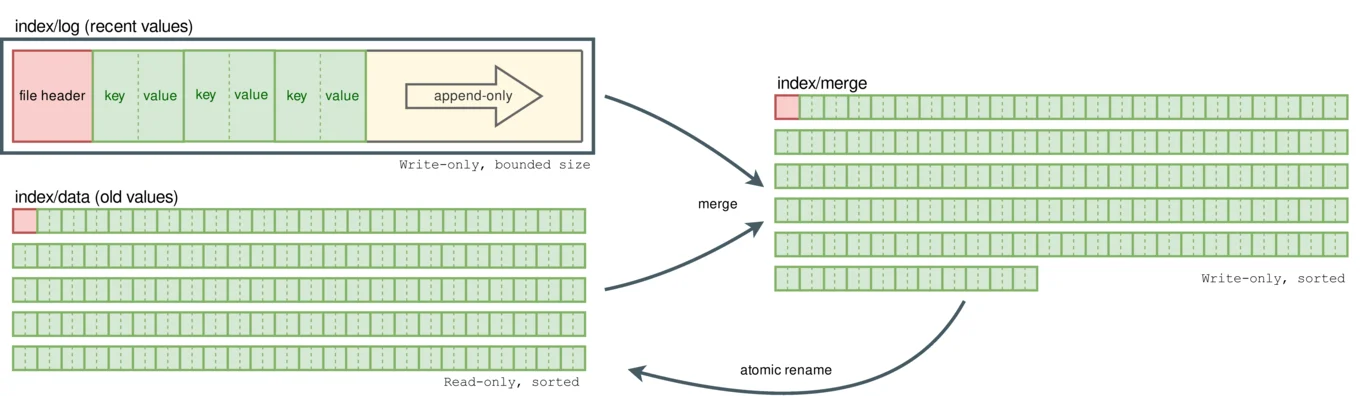
Our index is split into two major parts. The log is relatively small, and most
importantly, bounded; it contains the recently-added bindings. The data is
much larger, and contains older bindings.
The log part consists of a hash table associating keys to values. In order to
ensure concurrent access, and to be able to recover on a crash, we also maintain
a write-only, append-only file with the same contents, such that both always
contain exactly the same data at any time.
When a new key-value binding is added index, the value is simply serialized
along with its key and added to the log.
An obvious caveat of this approach is that the in-memory representation of the
log (the hashtable) is unbounded. It also grows a lot, as the Tezos node
stores more that 400 million objects. Our memory constraint obviously does not
allow such unbounded structures. This is where the data part comes in.
When the log size reaches a – customizable – threshold, its bindings are
flushed into a data component, that may already contain flushed data from
former log overloads. We call this operation a merge.
The important invariant maintained by the merge operation is that the data
file must remain sorted by the hash of the bindings. This will enable a fast
recovery of the data.
During this operation, both the log and the former data are read in sorted
order – data is already sorted, and log is small thus easy to sort in
memory – and merged into a merging_data file. This file is atomically renamed
at the end of the operation to replace the older data while still ensuring
correct concurrent accesses.
This operation obviously needs to re-write the whole index, so its execution is very expensive. For this reason, it is performed by a separate thread in the background to still allow regular use of the index and be transparent to the user.
In the meantime, a log_async – similar to log, with a file and a hash table
– is used to hold new bindings and ensure the data being merged and the new data
are correctly separated. At the end of the merge, the log_async becomes the
new log and is cleared to be ready for the next merge.
Recovering the data
This design allows us a fast lookup of the data present in the index. Whenever
find or mem is called, we first look into the log, which is simply a call
to the corresponding Hashtbl function, since this data is contained in memory.
If the data is not found in the log, the data file will be browsed. This
means access to recent values is generally faster, because it does not require
any access to the disk.
Searching in the data file is made efficient by the invariant that we kept
during the merge: the file is sorted by hash. The search algorithm consists in
an interpolation search, which is permitted by the even distribution of the
hashes that we store. The theoretical complexity of the interpolation search is
O(log (log n)), which is generally better than a binary search, provided that
the computation of the interpolant is cheaper than reads, which is the case
here.
This approach allows us to find the data using approximately 5-6 reading steps
in the file, which is good, but still a source of slowdowns. For this reason, we
use a fan-out module on top of the interpolation search, able to tell us the
exact page in which a given key is located, in constant time, for an additional
space cost of ~100 Mb. We use this to find the correct page of the disk, then
run the interpolation search in that page only. That approach allows us to find
the correct value with a single read in the data file.
Conclusion
This new backend is now used byt the Tezos nodes in production, and manages to
reduce the storage size from 250 Gb down to 25 Gb, with a monthly growth
rate of 2 Gb , achieving a tenfold reduction.
In the meantime, it provides and single writer, multiple readers access pattern that enables bakers and clients to connect to the same storage while it is operated.
On the memory side, all our components are memory bounded, and the bound is
generally customizable, the largest source of memory usage being the log part
of the index. While it can be reduced to fit in 1 Gb of memory and run on
small VPS or Raspberry Pi, one can easily set a higher memory limit on a more
powerful machine, and achieve even better time performance.
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.