
Irmin on MirageOS: Under-the-Hood With Notafs
Principal Software Engineer
In part one of our series on Notafs, we outlined the motivations and challenges behind creating a file system for MirageOS tailored to the SpaceOS use case of storing large files on disk in satellites. Furthermore, Notafs can be used to run the irmin-pack backend of Irmin, which, in turn, provides users with an amazing file system for their MirageOS projects.
In this post, we delve into more detail concerning the design choices behind Notafs and provide some benchmarks and visualisations to give you a better understanding of the file system. Let's dig in!
Big Design Decisions: Copy-on-Write
The Limits of File Systems
In our previous post, we mentioned some of the expectations of file systems to resist corruption and data loss. Ensuring these conditions are met can be challenging since hardware exhibits many failure modes. For example, it is impossible to check if a disk has physically persisted a write operation. In order to improve performance, disks use RAM buffering to quickly store the write requests before committing them persistently (which is a much slower process). Short of unplugging the disk and waiting for its internal battery and RAM to clear before rebooting, we can't know that the writes were executed and must be ready for the worst-case scenario: unwritten, partially written, or corrupted data regions on the disk! Writes could also be reordered, leading to consistency issues.
Furthermore, the way that disks are structured presents its challenges. Disks are organised into blocks of fixed sizes, like 512 bytes, 1 kb, or 4kb, depending on the model. A block is the smallest unit we can read or write, so even if we only want to update a few bytes on the disk, we still need to re-write the full surrounding block data. Different disk models can have additional constraints, such as:
- Hard drives that favour contiguous block reads and writes to ensure high performance since spinning their head to random locations is expensive.
- SSD exhibits faster wear if one block is updated more often than the others, leading to a shorter device life than what's expected under uniform usage.
All About Copy-on-Write
Considering these factors, Notafs was designed as a copy-on-write file system. This strong design principle means that when we update the file system, we never override a block in place but rather write the new data block in a new, unused location on the disk. Preserving the old block means that Notafs maintains access to a backup until the block is reused. If a write operation fails, for example, in case of a power outage in the middle of multiple block updates, Notafs can recover information from the old block.
This strategy does not impact performance since writing the new data in a new location or in place is virtually indistinguishable from the disk's perspective. From an implementation standpoint, copy-on-write is very similar to how purely functional data structures work to provide fast updates. Only modified data needs to be copied, so fast updates are still possible, as sharing unmodified content between revisions is free.
To implement the copy-on-write design, we needed to keep track of the unused free blocks where writes can be performed. This is akin to the challenge of implementing a memory allocator, but it is made slightly simpler because we only need to allocate fixed-size blocks. Our block allocator is backed by a queue containing the list of free block identifiers. After formatting a disk, the queue is (virtually) initialised to contain all block locations except a couple of reserved blocks. When a new block needs to be written to the disk, we pick a free block location from the queue where the write should take place. Filesystem operations are carefully implemented to free old blocks which aren't reachable anymore by pushing their block identifier location back onto the queue. Once the disk is full, these free blocks will eventually be reused to store new data. At the same time, old data is kept intact and can be used as a backup if needed. To avoid complications in determining if and when a block can be freed, we enforce strict linear ownership of blocks so that we do not need any reference counting or advanced garbage collection.
The queue of free blocks is part of the file system state and must be recoverable when we boot it. This is why the queue state itself is backed by a copy-on-write data structure, which is stored on disk! To ensure good performance, the block locations that have been freed during a single file system operation are sorted before being pushed to the queue. This process favours the allocation of contiguous block locations, leading to faster writes on hard drives. Consecutive block locations are also compressed in the queue by representing them as intervals instead of listing all the intermediate block locations.
When the disk gets full, the previously freed blocks will eventually be reused, storing new data. When that happens, the queue guarantees that we use the blocks that have been free for the longest time so that only the oldest backups become unrecoverable. However, since reusing blocks can lead to data consistency issues if some writes fail to be committed on disk, we needed a way to detect whether a block contains the expected latest data or the old partially-written/corrupted data. To this end, we use a checksum of the stored data to validate each block. We could have stored the checksum in the block next to the data it validates, but it would only have allowed for the detection of corrupted data and not for detecting whether the block's data is old since the old checksum remains valid. So, instead, we store the checksum in the parent block next to the block location it validates. When a parent block needs to read one of its child block's data, it uses its checksum to verify that its child data is as expected.
Final Considerations
There was one last issue for our team to tackle regarding the design: if everything is copy-on-write and the new filesystem root is written to a new block every time, how do we find the location of the latest root when the unikernel boots? We wanted to avoid scanning the whole disk in search of the latest root. Hence, when formatting a new disk, we reserved a fixed number of blocks at known locations. After each file system update, one of these blocks is updated in place to point to the latest root allocation in a round-robin fashion, with a generation counter to help our application determine which one was written last.
When the filesystem starts, it identifies the latest root from the reserved blocks and traverses all of its reachable data to check each block checksum and validate that the whole filesystem is in a consistent state. If an issue is detected, implying the disk wasn't shut down properly, Notafs will attempt to use the previous filesystem root found in the previous reserved block. This procedure effectively rolls back the failed write operation until a valid filesystem state is found (or the disk is deemed unrecoverable!). To avoid SSD wear from updating the reserved root blocks too often compared to other blocks, we have added an extra, dynamically allocated level of indirection to the previous explanations, which amortises the number of updates to the reserved blocks.
Finally, we implemented several optimisations to the above scheme to best use runtime resources. For example, we save disk space by representing block locations with as few bytes as possible, depending on the disk size. A 'Least-Recently-Used (LRU) cache keeps track of the latest reads and bufferises the incoming writes. This LRU enables Notafs to run with very low memory overhead, even when a file system operation would have required more RAM if another system had performed it.
We are very happy with this design because it combines simplicity with high data consistency guarantees. We used the setup to implement a copy-on-write rope data structure to represent files of any size with fast updates and read operations. We added a rudimentary hierarchical structure of folders and files on top to enable multiple file usage. This last part has not been optimised and is only suitable for applications with a low number of files. It will get slower the more files you have, but there are no hard limits.
Benchmarks and Tests
Since filesystem correctness is critical, we tested all steps of the project to validate our solution. Of special interest is the final verification that our team realised with the Gospel specification language using Ortac to translate the specification into a QCheck test suite from the formal spec. By comparing the behaviour of our Notafs file system with an obviously correct in-memory reference model, we could stress-test our system by simulating a huge number of tests to detect discrepancies. Our experience with Gospel made a strong case for it being the future of documentation, with high-level specifications that are both mechanically verifiable and readable by end-users.
Ultimately, correctness alone was not enough to justify using Notafs in production if it did not meet our performance goals. We benchmarked Notafs in comparison to existing MirageOS file systems for the features that were critical for SpaceOS and Irmin support. Those features were the ability to write large files, to read back those files, and to read only a sub-range in those files (a feature required by irmin-pack).
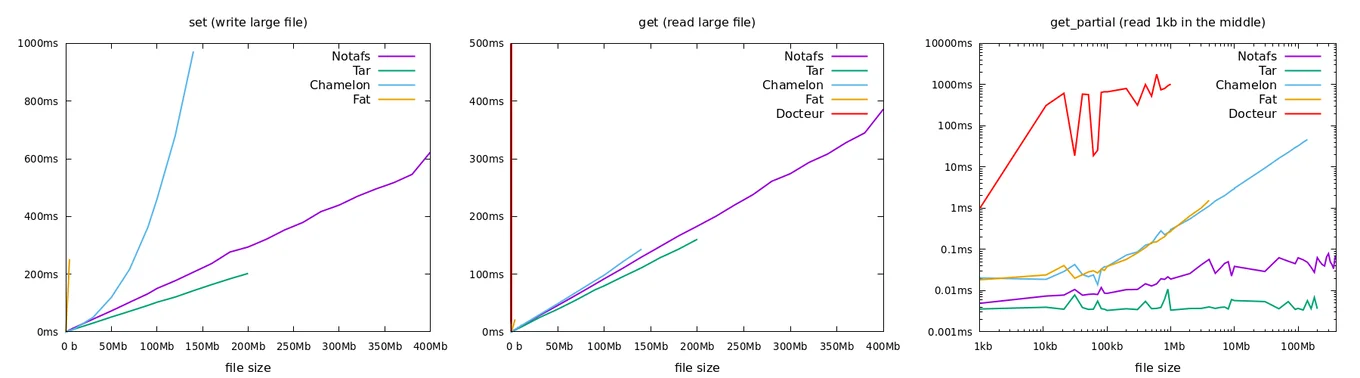
While the TAR file format will always be the fastest thanks to its simplicity, it comes with the limitation that files can't be removed or updated (hence eventually running out of disk space!). In general, the benchmarks confirm that Notafs meets its goal of handling large files efficiently. In particular, its careful use of memory with LRU enables Notafs to run the benchmarks on larger files than the alternative – for unikernels with restricted max memory usage. Note that benchmarks are always subject to interpretation; we did not benchmark the scenarios where we expect Notafs to perform the worst, e.g. with a large number of small files!
Our next image is actually a video showing Irmin running on top of a small Notafs disk. It combines everything we have explained so far: (epilepsy warning: the video displays flashing lights)
- The disk is divided into blocks of 1024-sized bytes, conveniently represented by 32x 32px squares. The blocks in colour contain live data used by the Irmin store, while the grey crossed-out ones are the free blocks. The colourful blocks create distinctive patterns that indicate the different types of data that Irmin uses to store the database.
- As more Irmin operations occur during the test's execution, you can see the Notafs block allocator in action, circling around the disk to write new data to the oldest freed block.
- At the bottom of the video, two histograms show the distribution of the reads and writes on each block to check that fair usage of each block is achieved.
- Finally, we can see the Irmin garbage collector clearing its old history on a frequent basis to avoid running out of disk space.
This visualisation was made possible because MirageOS libraries can also be used on standard operating systems without requiring special compilation by a unikernel. In other words, Notafs also enables Irmin to be used as a single-file database (like sqlite, which might be of interest for some applications' workflows. We want to do more work on this front to lift the limitation that the database size must currently be fixed in advance when formatting the disk.
Conclusion
Developing a new filesystem has been a very exciting project, and we hope that you'll enjoy the new options when developing unikernels with MirageOS:
- Notafs: for applications which require a limited number of very large files (e.g. SpaceOS satellite pictures).
- Irmin on Notafs: for a general-purpose file system, including optimisations to support a large number of arbitrarily sized files and many advanced features (with the caveat that this version of Irmin requires OCaml 5, which is still experimental on MirageOS).
We invite you to participate and try Notafs yourself! Please consult the open-source Notafs repository for further information, and share your experience (good and bad!) with the team. You can stay in touch with us on Bluesky, Mastodon, Threads, and LinkedIn.
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.