
OCaml 5 Multicore Testing Tools
Principal Software Engineer
The new version of OCaml 5 is here! It brings the ability to program multicore applications and to maximise our usage of all the CPU cores without a global lock getting in the way of performance. What's most exciting to me though is that we have a whole new way of writing... bugs!
And with so much potential for mistakes comes a new era of testing tools to help us write correct applications:
Memory Model
The first of those is the memory model of OCaml 5. If you already know what those two words mean, please skip this part because I won't pretend that I do. (I'm still convinced that it's just some fancy legalese terms to confuse people.) But it may actually matter when you realise that you've been living in a fantasy your whole CPU life:
left := 42 ;
right := 0 ;
When I read these two lines, I have years of beliefs telling me that the reference left will be updated before the right one is. But modern compilers and hardware conspire to break any sanity that may exist in my brain. You see, the order of operations doesn't actually matter if you can't see that the CPU is doing things in another order. It may just happen that the compiler or CPU will choose to do those two operations in reverse if they think it would be more convenient. And without this, our software would be so much slower that "instructions are executed in order" is an essential lie. (Well, is it even a lie if it makes no difference?)
To catch a liar, you need a second observer to correlate their claims. This is exactly what the other CPU cores will do. The bad news is that they are not actively looking for bad behavior from their colleagues, but they will end up reading values that aren't quite written in the order expected. This will wreak havoc into your invariants and trigger very, very weird bugs.
I'm not kidding when I say "very, very weird." Below is a real example of an out-of-order read/write that happened on my computer. This was a very simple program, with only two references, left and right, that got updated by two different domains (shown as two branches here):
!left = 42
!right = 0
|
.------------------------------------.
| |
| left := 1
| right := 2
right := 3 |
!left = 42 !right = 3
^^^^
how?
I tried to align the sequence of operations according to the observed memory values, but no ordering actually made sense. We can't have both !left = 42 and !right = 3 in the end.
Here's another attempt to align the instructions in a coherent way:
!left = 42
!right = 0
|
.------------------------------------.
| |
right := 3 |
!left = 42 |
left := 1
right := 2
!right = 3
^^^^
how?
It already requires some time to unpack this short example, but imagine how bad it would get to debug such a thing in production!
I want to stress that this specific execution wasn't the result of a compiler optimisation that we could have discovered by reading the assembly code. The program was running just fine over many iterations before being disturbed by a sudden hardware optimisation. The probability of observing this behavior from your CPU is very low---not low enough that you can ignore it, but you won't be able to reproduce this exact bug in any reasonable time. (But we'll see how to catch our CPU cores red-handed in the following sections!)
But ok, wait---come again. How is any of this nonsense a good memory model? For starters, the values you can read "out-of-order" are still real values that have been assigned to the references, not imaginary ones. Yes, it could be even weirder, but you don't want to know. It's all fun and games with integers, but this property really matters for pointers (where following the wrong one would lead you down a segmentation fault). You need to be wary of this in other languages, but not in OCaml. Memory safety is preserved. It's not an instant Game Over to do an accidental out-of-order read.
Secondly, when reading and writing to shared memory, you should use the new Atomic module to ensure the proper memory ordering of operations. This will introduce the required memory barriers to bring back sanity---at a small performance cost---so it's opt-in and only required for shared memory! (Note: you can also use a Mutex lock to protect your read/write into shared memory.)
In technical words, OCaml 5 programs enjoy the "Sequential Consistency for Data Race Freedom (DRF-SC)" property. If your program has no data races, then you can reason about your code under sequential consistency where the operations from different threads are interleaved with each other, but the instructions don't seem to be executed out of order.
Read more about the memory model in the OCaml 5 manual
By using Atomic, we are back in the wonderful land where operations happen in the expected order! The memory model becomes a tool for your brain, enabling it to reason about your algorithms. This one is so intuitive that I can once again pretend that it doesn't exist (without getting hit by an unexpected bug later.)
ThreadSanitizer
Alright, so how do we check that our programs aren't susceptible to an "out-of-order" bug caused by a missing Atomic or Mutex? ThreadSanitizer was created by Google as a lightweight instrumentation to discover these runtime data races.
To enable it on your OCaml program, you’ll need a special compiler that adds the required instrumentation to your software. Don't worry, it’s super easy to setup thanks to opam switches!
Install and usage informations on the ocaml-tsan repository
As a running example to demonstrate the usefulness of each tool, let's look at different implementations of simple banking accounts, where users can transfer money to each other if they have enough money in their account:
module Bank = struct
type t = int array
let transfer t from_account to_account money =
if money > 0 (* no negative transfer! *)
&& from_account <> to_account (* or transfer to self! *)
&& t.(from_account) >= money (* and you must have enough money! *)
then begin
t.(from_account) <- t.(from_account) - money ;
t.(to_account) <- t.(to_account) + money ;
end
end
This module could be part of a much larger program that receives transaction requests from the network and handles them. For simplicity here, we'll only be running a small simulation, but ThreadSanitizer is intended to be used on large real programs with messy I/O and side effects, not just broken toys and unit tests.
let t : Bank.t = Array.make 8 100 (* 8 accounts with $100 each *)
let money_shuffle () = (* simulate an economy *)
for _ = 0 to 10 do
Unix.sleepf 0.1 ; (* wait for a network request *)
Bank.transfer t (Random.int 8) (Random.int 8) 1 ; (* transfer $1 *)
done
let account_balances () = (* inspect the bank accounts *)
for _ = 0 to 10 do
Array.iter (Format.printf "%i ") t ; Format.printf "@." ;
Unix.sleepf 0.1 ;
done
let () = (* run the simulation and the debug view in parallel *)
[| Domain.spawn money_shuffle ; Domain.spawn account_balances |]
|> Array.iter Domain.join
It should be pretty clear that our code is not thread-safe and that transferring money while printing the account balances is asking for trouble! Running it with ThreadSanitizer enabled will print warnings into the terminal as soon as a potential data-race is observed (and it's even better in real life as the output is colorful!):
WARNING: ThreadSanitizer: data race (pid=1178477)
Write of size 8 at 0x7fc4936fd6b0 by thread T4 (mutexes: write M87):
#0 camlDune__exe__V0.transfer_317 <null> (v0.exe+0x6ae1a)
#1 camlDune__exe__V0.money_shuffle_325 <null> (v0.exe+0x6af8d)
.. ...
Previous read of size 8 at 0x7fc4936fd6b0 by thread T1 (mutexes: write M83):
#0 camlStdlib__Array.iter_329 <null> (v0.exe+0x9c675)
#1 camlDune__exe__V0.account_balances_563 <null> (v0.exe+0x6b054)
.. ...
The issue is reported very clearly thanks to the two conflicting stacktraces. There's a read/write data-race happening between the money_shuffle execution and the account_balances one, which could result in unreasonable memory reordering artifacts. In fact, it would be even worse if we were to transfer money from multiple domains in parallel (which we'll attempt to do in the next section as an interesting way of speeding up our bank transactions with Multicore).
It looks like we can fix the read/write data-race by adding a Mutex lock around the transfer function write operations:
let lock = Mutex.create ()
let transfer t from_account to_account money =
Mutex.lock lock ;
(* ... same as before ... *)
Mutex.unlock lock
But ThreadSanitizer is not easily fooled and will still complain loudly. We also need to use the same Mutex to protect the array reads in the account_balances function, as it would otherwise be perfectly valid to optimise away the shared memory reads into oblivion:
let account_balances_optimized () = (* faster... but wrong-er! *)
let str = String.concat " " @@ Array.of_list @@ Array.map string_of_int t in
for _ = 0 to 10 do
Format.printf "%s @." str ;
Unix.sleepf 0.1 ;
done
The data races reported by ThreadSanitizer are not only the ones where an absurd “out-of-order” happened, but preemptively, all those that could potentially trigger such a problem. If you are porting an existing multi-threaded application to OCaml 5, this compiler variant should probably be your default debug build.
Note that the ThreadSanitizer instrumentation does add a performance cost and doesn't increase memory safety by itself. Run it for a bit, track down your shared memory misuses, and add the required Atomic and Mutex operations.
Multicore Tests: Lin (and STM)
How do we unit test our Multicore libraries? It's business as usual, and the standard Alcotest will do well, for example. But there are some new properties that we should look for when writing and using libraries in a multicore setting. Let's revisit the bank accounts implementation by using Atomic operations this time rather than a Mutex:
module Bank = struct
type t = int Atomic.t array
let get t client = Atomic.get t.(client)
let transfer t from_account to_account money =
if money > 0
&& from_account <> to_account
&& get t from_account >= money
then begin
(* [fetch_and_add x v] is an atomic operation that does [x := !x + v] *)
let _ : int = Atomic.fetch_and_add t.(from_account) (- money) in
let _ : int = Atomic.fetch_and_add t.(to_account) money in
()
end
end
See how careful I was to use Atomic to read and write from shared memory? (I even used a fancy fetch_and_add!) Therefore, it must be correct if used by different domains, right? While this program doesn't have a data race, the definition of "correctness" is more subtle in a multicore setting.
It's easier to explain if I show you the problem. To test this interface with the Lin library, we only need to describe how to initialise a new bank and the API signature of available functions:
open Lin
module Bank_test = struct
type t = Bank.t
let init () = (* 8 accounts with $100 each *)
Array.init 8 (fun _ -> Atomic.make 100)
let cleanup _ = ()
let account = int_bound 7 (* array index between 0..7 *)
let api = [
val_ "get" Bank.get (t @-> account @-> returning int) ;
val_ "transfer" Bank.transfer
(t @-> account @-> account @-> nat_small @-> returning unit) ;
]
end
module Run = Lin_domain.Make (Bank_test)
let () =
QCheck_base_runner.run_tests_main [Run.lin_test ~count:1000 ~name:"Bank"]
That's all! A small DSL to define the types of our functions and we are done. Run this test to admire the beautiful ASCII art... craAaAash:
Results incompatible with sequential execution
|
|
.------------------------------------.
| |
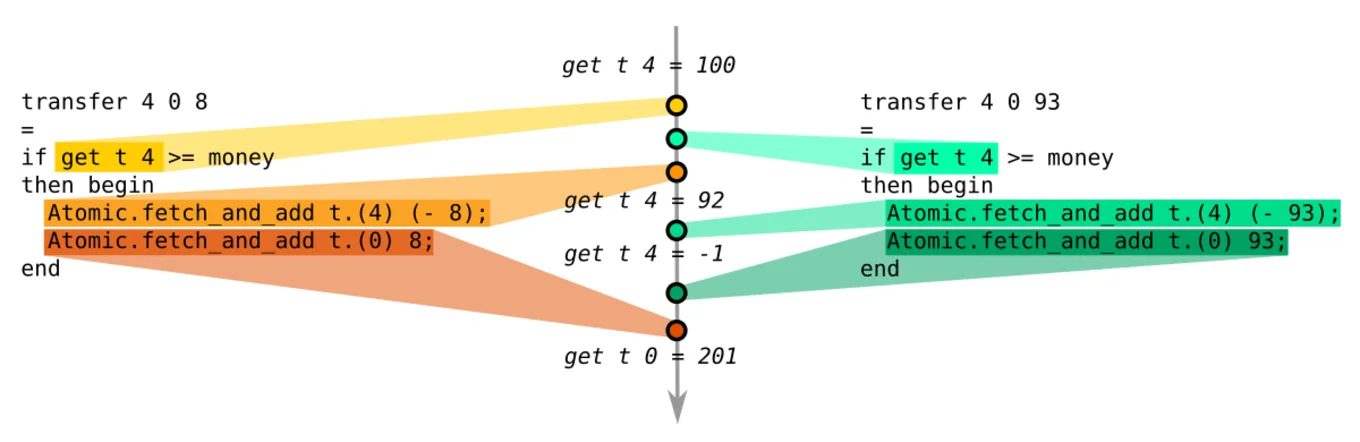
transfer t 4 0 8 : () transfer t 4 0 93 : ()
get t 4 : -1
Lin found a bug! The account number 4 is trying to simultaneously transfer $8 and $93 to account number 0. It then naturally ends up with a negative $1 on its account, which is obviously bad for a banking system... but we never told Lin that this was illegal, so why is it complaining?
In the tradition of QuickCheck, Lin not only generates random arguments to test our API, but it also creates full programs to execute on two domains. It then runs these generated programs and checks if the intermediate results are "sequentially consistent," the property of a well-behaved API where we can always explain its multicore behavior as a linear execution of the calls on a single core.
Without this "sequential consistency" property, the internals of our functions leak when multiple cores interleave their execution. In the example above, it wouldn't be possible to reach a negative $1 account on a single core, so Lin reports that sequential consistency is broken. It doesn't know that negative accounts are illegal, but it knows that this state is unreachable without multicore shenanigans.
Even though this is not a data race, a user of our library would have an equally hard time understanding the outcomes of our functions, when they depend so much on their accidental interleaving. "It sometimes doesn't work" is not a bug report I wish to see!
An intuitive way of thinking about "sequential consistency" is that our functions should behave as if they were a single atomic operation: Either we see none of their side effects, or we see all of them. It shouldn't be possible to see an in between, as this would result in a non-sequentialisable execution.
Once again, the easiest solution here is to use a Mutex to lock all the accounts during a transfer and when reading an account balance. Run the test suite again with Lin, and yep, we are safe. The operations are now sequentially consistent! (But we don't need the Atomics anymore with the Mutex.)

I really like how low effort / high reward Lin is. In just a few lines of declarative code, we can check that our code is correct when running on multiple cores. It's very extensive in its testing, which is just what we need when bugs are this hard to reproduce. The Multicore testing suite also provides a state-machine interface STM, which allows you to specify more properties that your system should respect (not only sequential consistency, but custom business logic!)
More examples on the multicoretests repository
Fun fact: The earlier "out-of-order" memory read/write on mutable references was also generated by Lin. While this tool is not specialised like ThreadSanitizer for discovering data-races, it can still trigger and identify the hardware memory reordering since they produce outcome that can't be explained on a single core. Here's the complete test if you want to see your computer memory misbehaving optimising:
open Lin
module Int_array = struct
type t = int array
let init () = [| 0 ; 0 |]
let cleanup _ = ()
let index = int_bound 1
let api = [
val_ "get" Array.get (t @-> index @-> returning int) ;
val_ "set" Array.set (t @-> index @-> int @-> returning unit) ;
]
end
module Run = Lin_domain.Make (Int_array)
let () = QCheck_base_runner.run_tests_main [Run.lin_test ~count:10_000 ~name:"Array"]
Dscheck
While adding a Mutex restores the sequential consistency of the transfer function, it's unsatisfying to slow down all transactions with a global lock. Most transfers are going to happen on different accounts, so could we be more precise in our safety measures? This is far from easy with locks, if we don't want to end up bankrupt with hungry philosophers!
One alternative solution is called lock-free programming, and as the name implies, it gets rid of all the locks---but at the cost of more complex algorithms. By using only Atomic operations, there are ways of encoding our transfer operation without blocking the other cores (such that they don't get stuck waiting on the unrelated threads to finish their transaction).
Lock-free algorithms have a bad reputation of being crazy hard to implement correctly. It's very easy to convince yourself that you found the right solution, only to discover that your algorithm only works when the OS scheduler is on your side (which it generally is...until it isn't). This is another type of hard-to-reproduce bug. We can't coerce the OS scheduler to be evil when testing our software.
Our last testing tool is the library dscheck. It provides a way to exhaustively test all the possible schedulings of a Multicore execution in order to discover the worst-case scenario that would lead to a crash. It does so by simulating parallelism on a single core using concurrency, thanks to algebraic effects and a custom scheduler. Dscheck is very fast because it doesn't test all possible interleaving but only the ones that matters.
In order to use it, you only need to replace the Atomic module by a custom one, and then write your unit test. Here I simply copy-pasted the bug generated by Lin earlier:
module Atomic = Dscheck.TracedAtomic
module Test = Dscheck.TracedAtomic
module Bank = struct (* same as before, but now using the traced Atomic *) end
let test () =
let t = Array.init 2 (fun _ -> Atomic.make 100) in
Test.spawn (fun () -> Bank.transfer t 0 1 8) ; (* fake a Domain.spawn *)
Bank.transfer t 0 1 93 ;
assert (Bank.get t 0 >= 0)
let () = Test.trace test (* exhaustively test all interleaving *)
Dscheck will then run our test function multiple times, discovering all the interesting paths that the scheduler could lead us down, and finally outputs a visualisation describing the worst-case scheduling that lead to crashes:
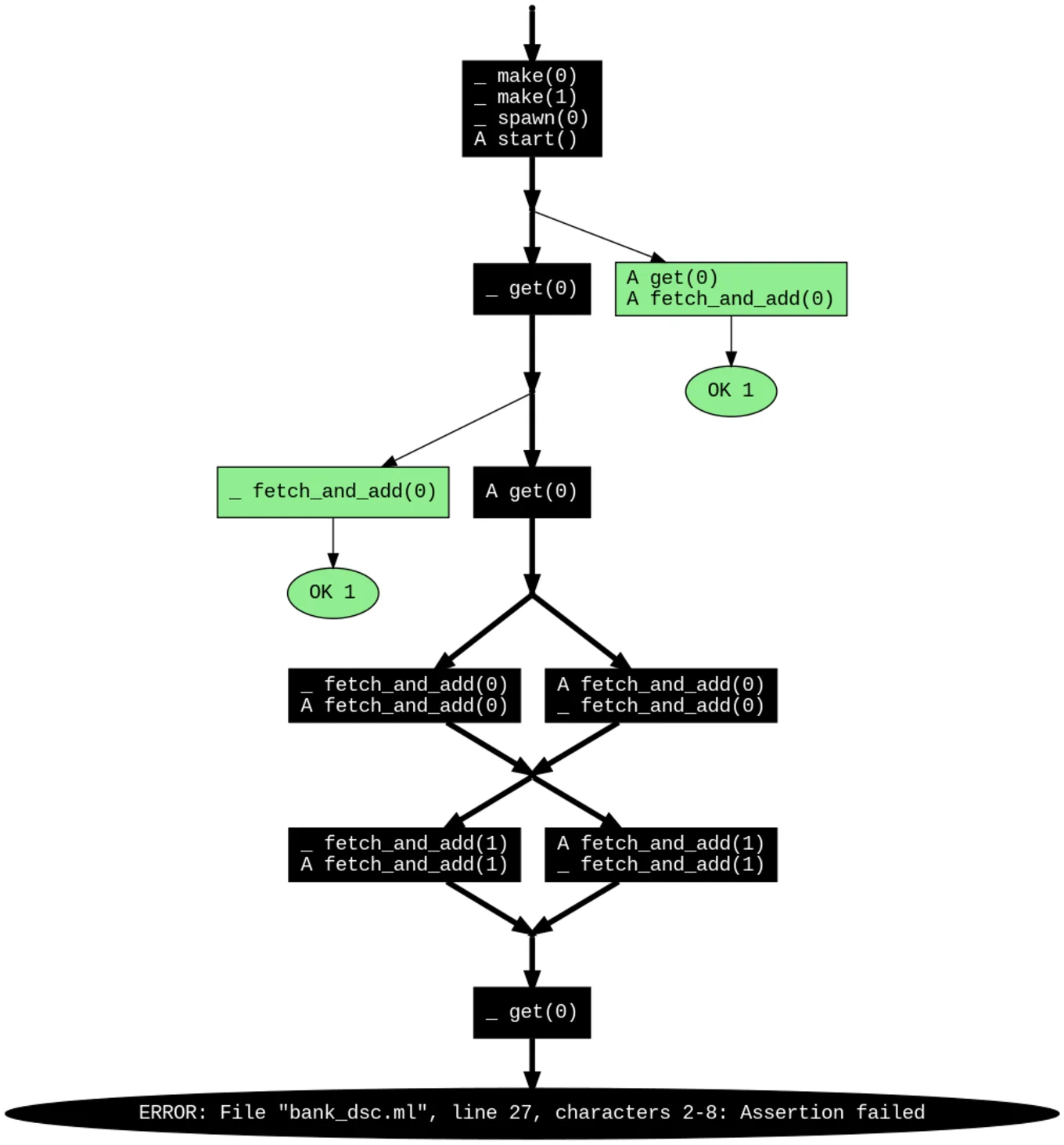
This is a low-level view of the bug. By inspecting the sequence of Atomic operations along the bad paths, we can discover the origin of the problem: the code is not careful when removing money from an account.
Perhaps this would work better:
let rec transfer t from_account to_account money =
let money_from = get t from_account in
if money > 0
&& from_account <> to_account
&& money_from >= money
then begin
if Atomic.compare_and_set t.(from_account) money_from (money_from - money)
then let _ : int = Atomic.fetch_and_add t.(to_account) money in ()
else transfer t from_account to_account money (* retry *)
end
And yes, Dscheck now happily validates all possible interleaving of this unit test!
More examples on the dscheck repository
So, does it mean our banking system works now? Nope! Lin reports new counter examples that break sequential consistency. I told you that lock-free was hard! Still, we can keep iterating, and we will eventually get it right because our tools remove the doubt and the impossibility of reproducibility that would otherwise make the task insurmountable. It's like having tiny assistants to double-check our assumptions. I love it. I've never been so excited to test my software!
get t 3 : 100
get t 4 : 100
|
.------------------------------------.
| |
| transfer t 4 3 10 : ()
get t 4 : 90
get t 3 : 100
^^^^^
how? account 4 sent the money, but account 3 didn't receive it!
Would you have caught this bug? Can you fix it? ;)
This was a tiny example, and it already brought some surprises. The multicore testing Lin, STM, and dscheck have been applied to real datastructures with great success. In fact, I wouldn't trust lock-free algorithms that were not validated by them.
Conclusion
It's 2022 and OCaml is finally Multicore. Even if this article is only scratching the surface of a specific itch, I hope it has convinced you that the Multicore metamorphose wasn't only about lifting a global lock somewhere in the runtime. A lot of care and attention also went into creating a great environment to tackle really hard problems. Here we've only looked at:
- The memory model to be able to reason about our programs
- ThreadSanitizer to detect dangerous use of shared memory
LinandSTMto discover logical bugs in a multicore setting- Dscheck to validate unit tests of lock-free algorithms by exhaustively checking all possible interleavings of their Atomic operations
There's still a lot more to discover in the latest release of OCaml. In the meantime, not only can we do Multicore, we can do it with confidence that our code works!
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.