
Up-to-Date Online Documentation

Senior Software Engineer
Into the Fire
The OCaml ecosystem relies on various resources and infrastructure such as ocaml.org, OCaml Docker images, opam-repo-ci, that are built and deployed using OCurrent. OCurrent is a library to express workflows and keep things up to date. As many of these projects are created using the same technology, it was interesting to centralise the documentation as it was spread throughout the various repositories. This post is about how we used OCurrent itself to automate this problem. We think it might also demonstrate how you can use OCurrent to automate some of yours!
Can't Keep My Eyes Off You
Before digging into the logic, it's essential to thoroughly define the problems in the documentation. The first problem was that the documentation lives in many GitHub repositories. Indeed, to make sure we update it whenever we modify the associated code, we keep the documentation closest to the code. The result is a repository organisation like this:
![]()
It's not a good judgement to count on humans' actions to monitor changes in all these repositories. As they fluctuate on their own time, we can't expect maintainers to backport documentation changes to the ocurrent.org website for each modification. To say it more technically, we need to track many files and keep them up to date. These actions should also update incrementally which matches with OCurrent nicely.
In addition, this documentation needs to stay up to date. Even if we centralise the documentation automatically, we must rebuild it regularly and fetch the changes from the repositories we track. Otherwise, the documentation will start to be outdated quickly. This is the opposite of what we want.
Furthermore, the system has to scale and be updated easily. Indeed, we would like to have the possibility to introduce new documents and repositories without having to install more applications. For instance, it would be beneficial to simply make a pull request somewhere.
In the next section, we will focus on the OCurrent pipeline design, which will automate our tasks and solve these problems.
Here I Dreamt I Was an Architect
The project is composed of several blocks we want to write to achieve our work:
- Fetch files from GitHub
- Rebuild a subset of the code
- Make the system modular
- Store and deploy the data easily
One aspect that will make our work a bit easier is to have it all concentrated in the same place, GitHub. As OCurrent provides a plugin to fetch information from GitHub, current_github, we don't have to worry about it. Furthermore, everything is cached thanks to OCurrent itself. We don't have to care about the incremental build. The only requirement is wisely choosing the data we want to cache.
Our architecture uses a trackers.yml file describing how the pipeline should interact with our heterogeneous repositories. It describes the files we want to track and where we would like them in the final website structure. The configuration gives a way to achieve modularity at a low cost, as we only have to open a PR on the repository that contains the tracker file to update them. Additionally, it allows us to track the repositories we want quickly. Once it's followed, we don't have to worry about the monitoring, as OCurrent can be set to rebuild stuff at the regular cycle. In our case, we want to control every week that the code hasn't mutated. In the present version of trackers.yml, we can specify the files we want to copy and the indexes we want to create to build our structure. This file is stored in the repository on which the GitHub App is installed.
Another critical component in the architecture is handling new files from the remote repository and integrating them into the website structure. This element is in charge of moving the piece from one part of the system to another. Moreover, it will have to ensure the paths are consistent and fail if not.
The last item must push the code to a specific Git repository because we decided to use GitHub Pages to store the website. To avoid issues with account management, it needs ssh to get access to a specific repository.
In the end, the pipeline design would look like this:
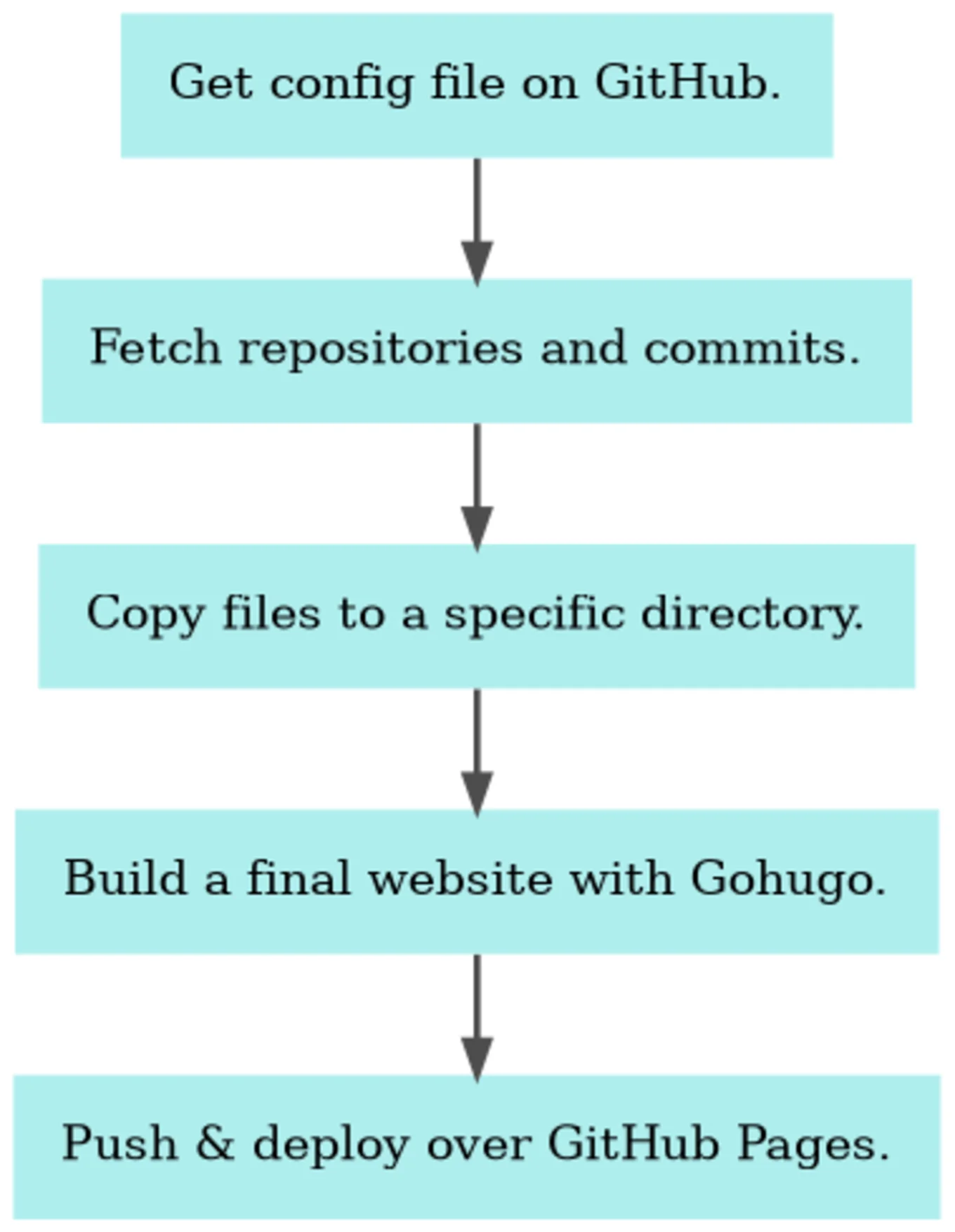
Now that we have our workflow let's see how it is implemented in practice!
This is How We Do It
In this section, we will focus on the way to implement this infrastructure. We won't view all the elements in detail, but we will try to concentrate on the most important ones, like how to create a custom ocurrent component and chain them together to build a pipeline.
current_github
Let's focus on a standard structure in an OCurrent project: the way to get the HEAD of a branch on GitHub and fetch the commit with Git. In the related code, we find the HEAD, then ask GitHub to give us information about the HEAD commit on the default branch and finally get the content with Git (it returns the related commit):
let fetch_commit ~github ~repo () =
let head = Current_github.API.head_commit GitHub repo in
let commit_id =
Current.map Current_github.Api.Commit.id head
in
let commit =
Current_git.fetch commit_id
in
commit
let main =
let github = (* GitHub App code *) in
let commit = fetch_commit ~github ~repo () in
(* Use the commit code *)
The documentation of current_github and current_git is available online.
Fetching the Files
As we know how to extract data from GitHub, applying the process to various repositories will be easy. It can be noticed that the commit element is of type Commit.t Current.t. To work with Current.t, we need to "unwrap" the object with specific functions like map and bind. This post does not present how to load the content from a Yaml file. We assume that we get a selection list Current.t, where selection is defined as:
type selection = {
repo : string;
commit : Current_git.Commit.t Current.t;
files : 'a list;
}
It contains the source repository, the commit associated with the specified branch, and the list of files to monitor from this repository.
To git clone the content, we must apply the fetch_commit function.
Copy the Content
In this subsection, we will see how we can define a custom component and how to make it interact with the rest of our code.
The component is in charge of fetching the content of the files from the source directory and storing it in memory. To trigger the action only when the content changes, we will define a Current_cache element. Thanks to OCurrent, the content is cached and only rebuilt on change or request.
It manipulates some File.info (source, destination, …) and produces a File.t when the content is read. File.t is simply a:
type File.t = {
metadata: File.info;
content: string list;
}
Our file is represented as a string list, as we need to be able to add more information. We know the size of the files is limited, so it is not an issue for us.
The component is defined as a Current_cache.BUILDER with whom the signature looks like this:
module type BUILDER = sig
type context
module Key : sig
type t
val digest:
end
module Value : sig
type t
val marshall : t -> string
val unmarshall : string -> t
end
val build :
context ->
Current.Job.t ->
Key.t ->
Value.t Current.or_error Lwt.t
end
As the Value and the Key modules only use functions to manipulate JSON, we can focus on the build function definition:
let build files job { Key.commit; Key.repo; _ } =
Current.Job.start job ~level:Current.Level.Average >>= fun () ->
Current_git.with_checkout ~job commit @@ fun dir ->
extract ~job ~dir repo files
>>= Lwt_result.return
It creates a temporary directory with the content fetched from Git. Then, it extracts the data as a File.t and returns the result. The interesting detail here is Current_git.with_checkout fn. It is used to copy our code somewhere in the system temporarily. Current.Job.start is just some boilerplate code to start a job asynchronously.
Consequently, we can give the builder a functor to construct our cache system. Moreover, we create a function associated with it thanks to the Content module newly created:
module Content = Current_cache.Make (Content)
let weekly = Current_cache.Schedule.v ~valid_for:(Duration.of_day 7) ()
let fetch ~repo ~ commit files =
Current.component "fetch-doc" |>
let> commit = commit in
Content.get ~schedule:weekly files
{content.Key.repo; Content.Key.commit }
We specify the date when the cache is invalidated to trigger the rebuild at least every week.
Build & Deploy
In this last subsection, we discuss how to write all the files stored in the cache to the right place in the filesystem. We use hugo to build the website and git with ssh to deploy it. As we expect the information to be cached, we build a Current_cache module again, where the build function is:
let build { files; indexes; conf } job { Key.commit; _ } =
Current.Job.start job ~level:Current.Level.Average >>= fun () ->
Current_git.with_checkout ~job commit @@ fun dir ->
write_all job dir files indexes >>= fun () ->
Lwt_result.bind (hugo ~cwd:dir job) (fun () ->
let f cwd =
let commit = Current_git.Commit.hash commit in
deploy_over_git ~cwd ~job ~conf dir commit
in
Current.Process.with_tmpdir f)
In this context, the pipeline creates an indexes file as _index.md. It's used by Hugo to build the directory structure. This function uses the same Current_git.checkout process to create a temporary directory containing the website's skeleton. All the work is done in the deploy_over_git function, but this is not relevant to go further in detail. The component writes all the File.t.content to the destination specified in their metadata. Once we have successfully written them, we generate the website with hugo --minify --output-dir=public/. Last but not least, we copy the content of the public repository to a fresh temporary one, so we can add the files with a git init and push our work to GitHub. Finally, on the target repository, GitHub Pages will deploy the website.
And voila, our website is up-to-date and online!
Happy Together
This blog post has described how we handle our distributed documentation and centralise it on our website. We have seen how to use some Current_* plugins and how to write our own. It was also the occasion to speak about various OCurrent structures.
If you are curious, you can check the code in the ocurrent/ocurrent.org repository. Feel free to look at the ocurrent.org built with this pipeline. The description of the pipeline is also available in the bin repository.
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.