
Benchmarking OCaml projects with current-bench

Software Engineer
Regular CI systems are optimised for workloads that do not require stable performance over time. This makes them unsuitable for running performance benchmarks.
current-bench provides a predictable environment for performance benchmarks and a UI for analysing results over time. Similar to a CI system, it runs on pull requests and branches which allows performance to be analysed and compared. It can currently be enabled as an app on GitHub repositories with zero configuration. Several public repositories are runningcurrent-bench, including Irmin and Dune. We plan to enable it on more projects in the future.
In this article, we give a technical overview of current-bench, showing how results are collected and analysed, requirements for using it and how we built the infrastructure for stable benchmarks. We also describe future work that would allow more OCaml projects to run current-bench.
Introduction
For performance critical software, we must run benchmarks to ensure that there's no regression. Running benchmarks before the user submits their pull request is tedious, and since every user might have a different machine, you can't be sure if the benchmarks performed actually improved or regressed performance.
Our current-bench aims to solve this problem by providing a stable benchmarking platform that runs every time the user submits a pull request and compares the result to the benchmarks on the main branch. As current-bench is zero-configuration, users can enroll their repository to run benchmarks with ease. This current-bench has helped projects ensure that regression doesn't happen, so you can merge code with more confidence.
Architecture
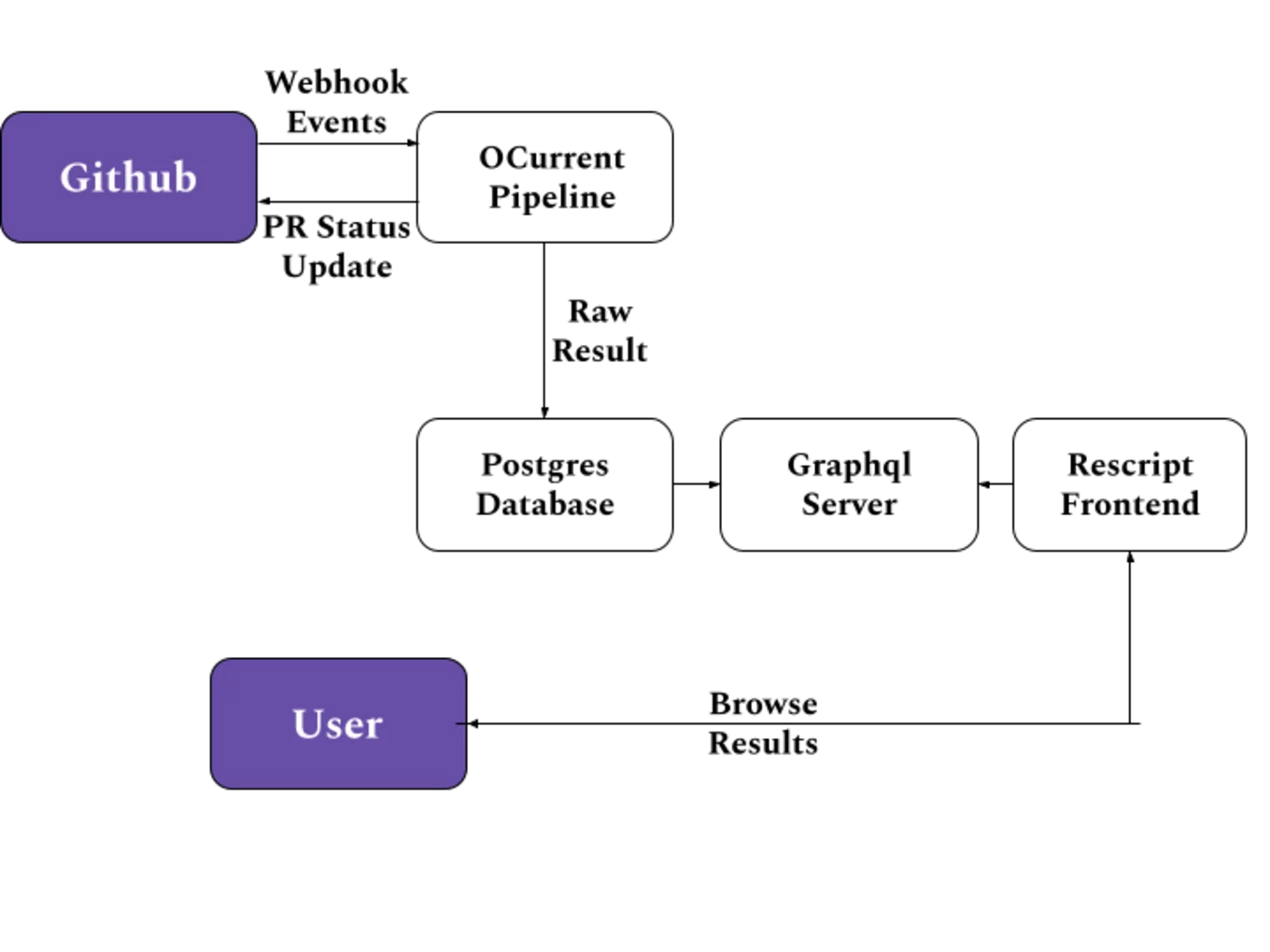
Benchmarking Pipeline
As shown in Figure 1 (above), the benchmarking infrastructure uses ocurrent1, an embedded Domain Specific Language to write a pipeline. The ocurrent command computes the build incrementally and helps with static analysis. Whenever a pull request is opened on a repository monitored by current-bench, a POST request is sent to the server running the pipeline. The pipeline fetches the head commit on the pull request and uses Docker to compile the code, and then it runs the make bench command inside the generated Docker image.
The pipeline runs on a single node, and the process is pinned to a single core to ensure there's no contention of resources when running the benchmarks. Once finished, the raw JSON result is stored in a Postgres database, which the frontend can query using a GraphQL API, as shown in Figure 2 below.
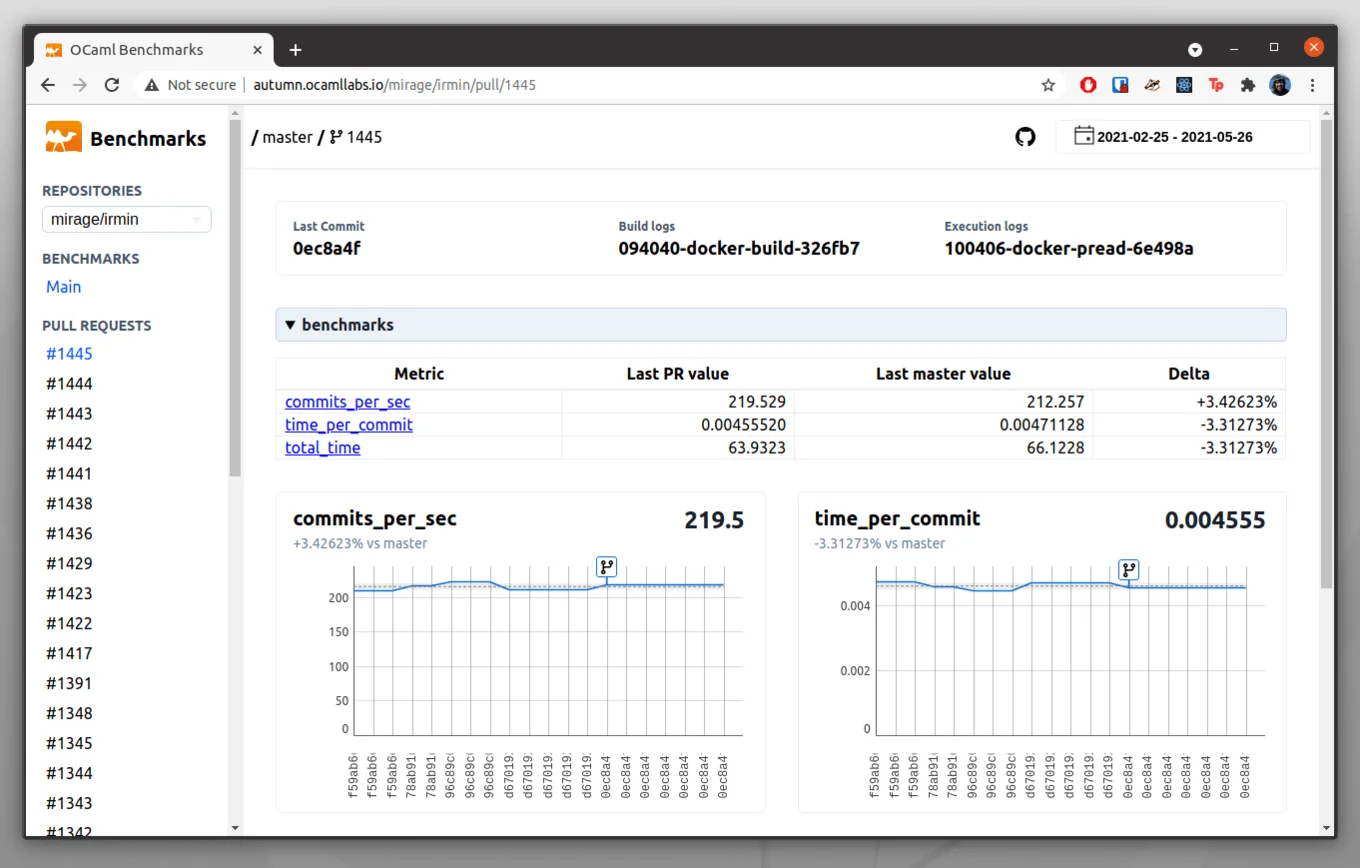
The frontend supports historical navigation and provides comparison with the default branch. It allows users to select a pull request of which they want to see the graphs. The graphs display the individual result of the head commit and the comparison with the commits on the default branch. The frontend permits users to select the historical interval when they want to compare benchmarks, and it also shows the standard deviation. Once the benchmarks have run successfully, the pipeline sets the pull request status to the frontend URL. Then the user can look at the graphs.
Hardware Optimisation
Our current-bench uses the hardware optimisations developed for OCaml multicore compiler benchmarks (presented at ICFP OCaml Workshop 2019) with a few modifications to allow the benchmarks to run inside Docker containers. To get stable performance, we configured the kernel to isolate some of the CPU cores. Linux then avoids scheduling other user processes automatically. We also disabled IRQ handling and power saving.
The container that runs the benchmark is pinned to one of the isolated cores. Since I/O operations can make the benchmarks less stable, we use an in-memory tmpfs partition in /dev/shm for all storage. For NUMA enabled systems, we configure this partition to be allocated on the NUMA node of the isolated core. The pipeline disables ASLR inside the container automatically, which is normally blocked by the default Docker seccomp profile, so we have modified the profile to allow the personality(2) syscall.
Enrolling a repository
To enroll a repository, you need to ensure the following:
- Enable the ocaml-benchmarks GitHub app for your repository.
- The repository needs a
benchMakefile target. This is triggered from thecurrent-benchpipeline. - The output of the
make benchtarget is JSON, which can be parsed by the pipeline and displayed by the frontend.
Future work
Anyone who wants to roll out a continuous, zero-configured benchmarking infrastructure can set up the current-bench infrastructure. In the future, we want to scale current-bench by isolating cores on multiple machines and adding a scheduler to ensure that benchmarks use only one core at a time per machine. We plan to add support for different benchmarking libraries that repositories can use—for example, we currently support repositories using bechamel. We also aim to make the adoption of current-bench easier by adding a conversion library that can convert any benchmark output into output parseable by current-bench. We intend to add support for quick and slow benchmarks, which would allow users to have faster feedback loops on pull requests while ensuring they can still run more extensive, time consuming benchmarks to see the performance.
Thank you for reading! You can check out the implementation for current-bench here!
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.