
Introducing the GraphQL API for Irmin 2.0
With the release of Irmin 2.0.0, we are happy to announce a new package - irmin-graphql, which can be used to serve data from Irmin over HTTP. This blog post will give you some examples to help you get started, there is also a section in the irmin-tutorial with similar information. To avoid writing the same thing twice, this post will cover the basics of getting started, plus a few interesting ideas for queries.
Getting the irmin-graphql server running from the command-line is easy:
$ irmin graphql --root=/tmp/irmin
where /tmp/irmin is the actual path to your repository. This will start the server on localhost:8080, but it's possible to customize this using the --address and --port flags.
The new GraphQL API has been added to address some of the shortcomings that have been identified with the old HTTP API, as well as enable a number of new features and capabilities.
GraphQL
GraphQL is a query language for exposing data as a graph via an API, typically using HTTP as a transport. The centerpiece of a GraphQL API is the schema, which describes the graph in terms of types and relationships between these types. The schema is accessible by the consumer, and acts as a contract between the API and the consumer, by clearly defining all API operations and fully assigning types to all interactions.
Viewing Irmin data as a graph turns out to be a natural and useful model. Concepts such as branches and commits fit in nicely, and the stored application data is organized as a tree. Such highly hierarchical data can be challenging to interact with using REST, but is easy to represent and navigate with GraphQL.
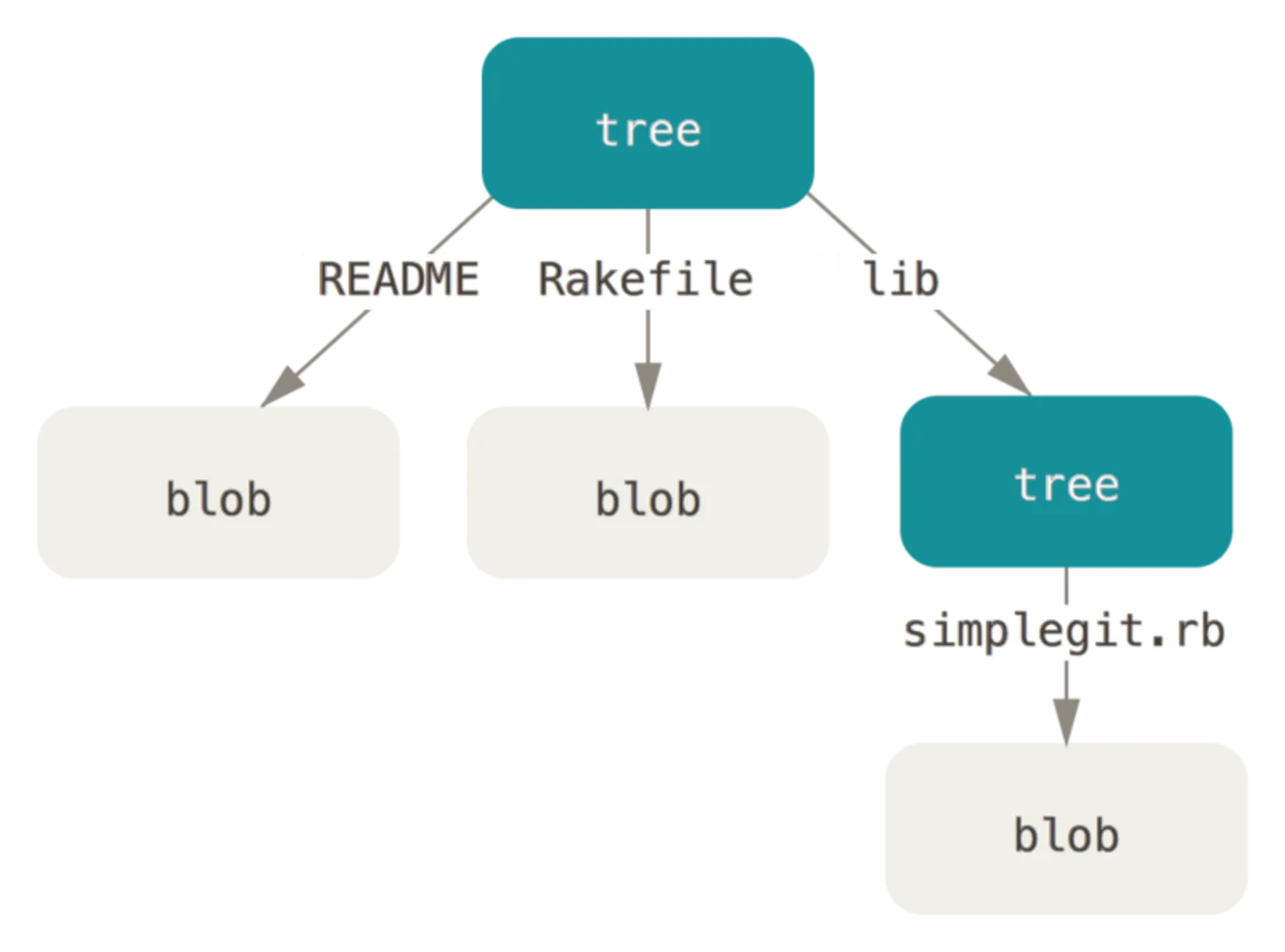 (image from Pro Git)
(image from Pro Git)
As a consumer of an API, one of the biggest initial challenges is understanding what operations are exposed and how to use them. Conversely, as a developer of an API, keeping documentation up-to-date is challenging and time consuming. Though no substitute for more free-form documentation, a GraphQL schema provides an excellent base line for understanding a GraphQL API that is guaranteed to be accurate and up-to-date. This issue is definitely true of the old Irmin HTTP API, which was hard to approach for newcomers due to lack of documentation.
Being able to inspect the schema of a GraphQL API enables powerful tooling. A great example of this is GraphiQL, which is a browser-based IDE for GraphQL queries. GraphiQL can serve both as an interactive API explorer and query designer with intelligent autocompletion, formatting and more.
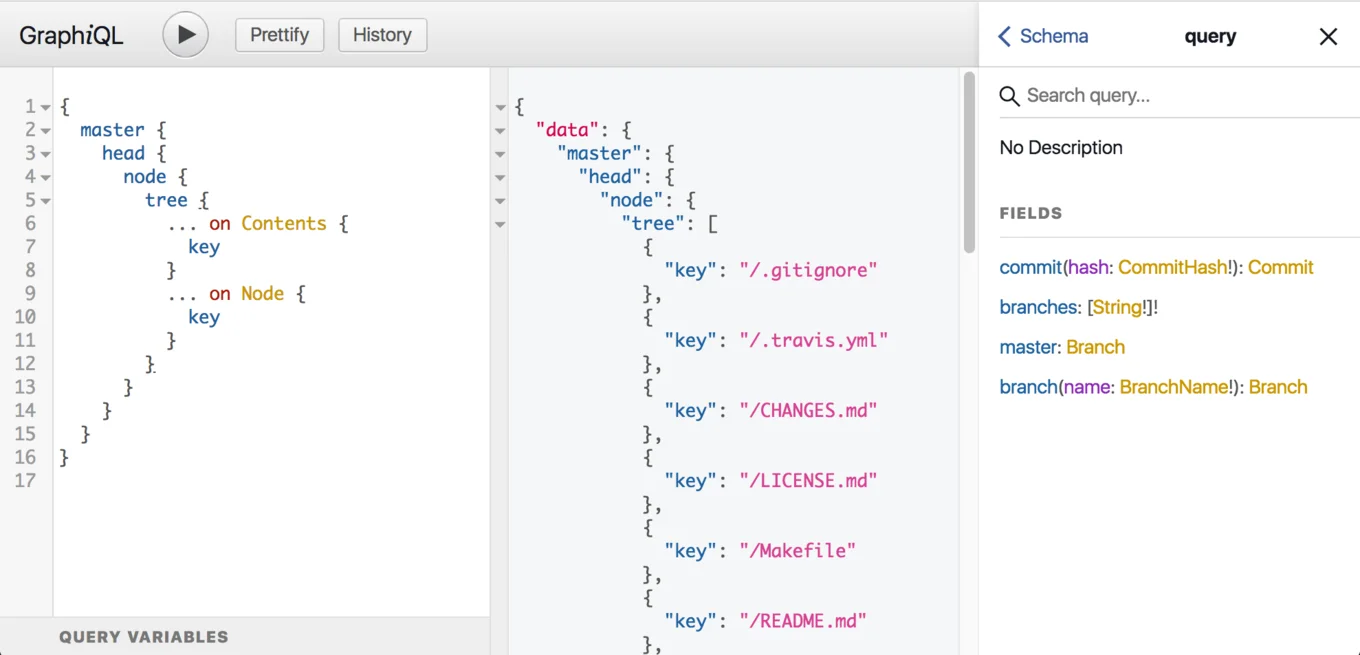
The combination of introspection and a strongly typed schema also allows creating smart clients using code generation. This is already a quite wide-spread idea with Apollo for iOS, Apollo for Android or graphql_ppx for OCaml/Reason. Though generic GraphQL client libraries will do a fine job interacting with the Irmin GraphQL API, these highlighted libraries will offer excellent ergonomics and type-safety out of the box.
One of the problems that GraphQL set out to solve is that of over- and underfetching. When designing REST API response payloads, there is always a tension between including too little data, which will require clients to make more network requests, and including too much data, which wastes resources for both client and server (serialization, network transfer, deserialization, etc).
The existing low-level Irmin HTTP API is a perfect example of this. Fetching the contents of a particular file on the master branch requires at least 4 HTTP requests (fetch the branch, fetch the commit, fetch the tree, fetch the blob), i.e. massive underfetching. By comparison, this is something easily solved with a single request to the new GraphQL API. More generally, the GraphQL API allows you to fetch exactly the data you need in a single request without making one-off endpoints.
For the curious, here's the GraphQL query to fetch the contents of README.md from the branch master:
query {
master {
tree {
get(key: "README.md")
}
}
}
The response will look something like this:
{
"data": {
"master": {
"tree": {
"get": "The contents of README.md"
}
}
}
}
The GraphQL API is not limited to only reading data, you can also write data to your Irmin store. Here's a simple example that will set the key README.md to "foo", and return the hash of that commit:
mutation {
set(key: "README.md", value: "foo") {
hash
}
}
By default, GraphQL allows you to do multiple operations in a single query, so you get bulk operations for free. Here's a more complex example that modifies two different branches, branch-a and branch-b, and then merges branch-b into branch-a all in a single query:
mutation {
branch_a: set(branch: "branch-a", key: "foo", value: "bar") {
hash
}
branch_b: set(branch: "branch-a", key: "baz", value: "qux") {
hash
}
merge_with_branch(branch: "branch-b", from: "branch-a") {
hash
tree {
list_contents_recursively {
key
value
}
}
}
}
Here's what the response might look like:
{
"data": {
"branch_a": {
"hash": "0a1313ae9dfe1d4339aee946dd76b383e02949b6"
},
"branch_b": {
"hash": "28855c277671ccc180c81058a28d3254f17d2f7b"
},
"merge_with_branch": {
"hash": "7b17437a16a858816d2710a94ccaa1b9c3506d1f",
"tree": {
"list_contents_recursively": [
{
"key": "/foo",
"value": "bar"
},
{
"key": "/baz",
"value": "qux"
}
]
}
}
}
}
Overall, the new GraphQL API operates at a much higher level than the old HTTP API, and offers a number of complex operations that were tricky to accomplish before.
Customizable
With GraphQL, all request and response data is fully described by the schema. Because Irmin allows the user to have custom content types, this leaves the question of what type to assign to such values. By default, the GraphQL API will expose all values as strings, i.e. the serialized version of the data that your application stores. This works quite well when Irmin is used as a simple key-value store, but it can be very inconvenient scheme when storing more complex values. As an example, consider storing contacts (name, email, phone, tags, etc) in your Irmin store, where values have the following type:
(* Custom content type: a contact *)
type contact = {
name : string;
email : string;
(* ... *)
}
Fetching such a value will by default be returned to the client as the JSON encoded representation. Assume we're storing a contact under the key john-doe, which we fetch with the following query:
query {
master {
tree {
get(key: "john-doe")
}
}
}
The response would then look something like this:
{
"master": {
"tree": {
"get": "{\"name\":\"John Doe\", \"email\": \"john.doe@gmail.com/", ...}"
}
}
}
The client will have to parse this JSON string and cannot choose to only fetch parts of the value (say, only the email). Optimally we would want the client to get a structured response such as the following:
{
"master": {
"tree": {
"get": {
"name": "John Doe",
"email": "john.doe@gmail.com",
...
}
}
}
}
To achieve this, the new GraphQL API allows providing an "output type" and an "input type" for most of the configurable types in your store (contents, key, metadata, hash, branch). The output type specifies how data is presented to the client, while the input type controls how data can be provided by the client. Let's take a closer look at specifying a custom output type.
Essentially you have to construct a value of type (unit, 'a option) Graphql_lwt.Schema.typ (from the graphql-lwt package), assuming your content type is 'a. We could construct a GraphQL object type for our example content type contact as follows:
(* (unit, contact option) Graphql_lwt.Schema.typ *)
let contact_schema_typ = Graphql_lwt.Schema.(obj "Contact"
~fields:(fun _ -> [
field "name"
~typ:(non_null string)
~args:[]
~resolve:(fun _ contact ->
contact.name
)
;
(* ... more fields *)
])
)
To use the custom type, you need to instantiate the functor Irmin_unix.Graphql.Server.Make_ext (assuming you're deploying to a Unix target) with an Irmin store (type Irmin.S) and a custom types module (type Irmin_graphql.Server.CUSTOM_TYPES). This requires a bit of plumbing:
(* Instantiate the Irmin functor somehow *)
module S : Irmin.S with type contents = contact =
(* ... *)
(* Custom GraphQL presentation module *)
module Custom_types = struct
(* Construct default GraphQL types *)
module Defaults = Irmin_graphql.Server.Default_types (S)
(* Use the default types for most things *)
module Key = Defaults.Key
module Metadata = Defaults.Metadata
module Hash = Defaults.Hash
module Branch = Defaults.Branch
(* Use custom output type for contents *)
module Contents = struct
include Defaults.Contents
let schema_typ = contact_schema_typ
end
end
module Remote = struct
let remote = Some s.remote
end
module GQL = Irmin_unix.Graphql.Server.Make_ext (S) (Remote) (Custom_types)
With this in hand, we can now query specifically for the email of john-doe:
query {
master {
tree {
get(key: "john-doe") {
email
}
}
}
}
... and get a nicely structured JSON response back:
{
"master": {
"tree": {
"get": {
"email": "john.doe@gmail.com"
}
}
}
}
The custom types is very powerful and opens up for transforming or enriching the data at query time, e.g. geocoding the address of a contact, or checking an on-line status.
Watches
A core feature of Irmin is the ability to watch for changes to the underlying data store in real-time. irmin-graphql takes advantage of GraphQL subscriptions to expose Irmin watches. Subscriptions are a relative recent addition to the GraphQL spec (June 2018), which allows clients to subscribe to changes. These changes are pushed to the client over a suitable transport mechanism, e.g. websockets, Server-Sent Events, or a chunked HTTP response, as a regular GraphQL response.
As an example, the following query watches for all changes and returns the new hash:
subscription {
watch {
commit {
hash
}
}
}
For every change, a message like the following will be sent:
{
"watch": {
"commit": {
"hash": "c01a59bacc16d89e9cdd344a969f494bb2698d8f"
}
}
}
Under the hood, subscriptions in irmin-graphql are implemented using Irmin watches, but this is opaque to the client -- this will work with any GraphQL spec compliant client!
Here's a video, which hows how the GraphQL response changes live as the Irmin store is being manipulated:
Note that the current implementation only supports websockets with more transport options coming soon.
Wrap-up
Irmin 2.0 ships with a powerful new GraphQL API, that makes it much easier to interact with Irmin over the network. This makes Irmin available for many more languages and contexts, not just applications using OCaml (or Javascript). The new API operates at a much high level than the old API, and offers advanced features such as "bring your own GraphQL types", and watching for changes via GraphQL subscriptions.
We're looking forward to seeing what you'll build with it!
Open-Source Development
Tarides champions open-source development. We create and maintain key features of the OCaml language in collaboration with the OCaml community. To learn more about how you can support our open-source work, discover our page on GitHub.
Explore Commercial Opportunities
We are always happy to discuss commercial opportunities around OCaml. We provide core services, including training, tailor-made tools, and secure solutions. Tarides can help your teams realise their vision
Stay Updated on OCaml and MirageOS!
Subscribe to our mailing list to receive the latest news from Tarides.
By signing up, you agree to receive emails from Tarides. You can unsubscribe at any time.